萬盛學電腦網 >> 數據庫 >> mssql數據庫 >> sql server 2008億萬數據性能優化
sql server 2008億萬數據性能優化
根據設計慣例,查詢的時候主子表通過關鍵詞字段關聯查詢,查詢語句如下:
select top 1000 a.word,a.queryurl,a.irank,a.title,a.baiduurl,a.itraffic1,a.itraffic2,b.ibaiduindex from zibiao a
with(nolock)
inner join zhubiao b with(nolock) on a.word=b.word
where a.queryurl='http://zhidao.baidu.com'
order by b.ibaiduindex desc,a.irank
發現速度很慢,快的時候瞬間,慢的時候長達幾分鐘。分析sql server的查詢執行計劃如下:

分析這個執行計劃圖,主要資源開銷是在主表的聚集索引查找,應該是子表根據網址找到關鍵詞後,再到主表中查找關鍵詞對應的指數的這一步比較耗時。
因這2個表的更新頻率非常高,以為是更新頻率太快,導致索引效率降低,於是想到用數據庫讀寫分離的方案,專門拿了一台備用服務器,通過發布訂閱的方法 ,將這兩張表發布到備用服務器上,專門在備用服務器上做查詢,發現速度並沒有得到提升。
在csdn上發了一個討論帖,網友討論很熱烈,sql server的很多版主都有參與討論,給出的方案也很多。有人說是IO讀寫瓶頸,於是升級了下服務器,硬盤采用raid10的固態硬盤,內存更是升級到了128G,不過效果仍舊不明顯,同樣的語句,慢的時候還是需要幾十秒。
有網友給出的方案,是建議把主表字段放到子表冗余,以減少關聯的資源消耗,再結合以上的執行計劃圖,確實瓶頸是在主表的的聚集索引查找上,於是單獨執行了下子表的irank排序語句:
select top 1000 a.word,a.queryurl,a.irank,a.title,a.baiduurl,a.itraffic1,a.itraffic2 from zibiao a
with(nolock)
where a.queryurl='http://zhidao.baidu.com'
order by a.irank
發現執行速度非常快,幾乎秒開了,當然irank字段上有建索引的。
測試成功,於是將主表的ibaiduindex字段放到子表冗余,並且建立好索引(這裡的索引建立是有技巧的)。執行語句:
select top 1000 a.word,a.queryurl,a.irank,a.title,a.baiduurl,a.itraffic1,a.itraffic2,a.ibaiduindex from zibiao a
with(nolock)
where a.queryurl='http://zhidao.baidu.com'
order by a.ibaiduindex desc,a.irank
查詢瞬間出來結果。執行計劃如下:
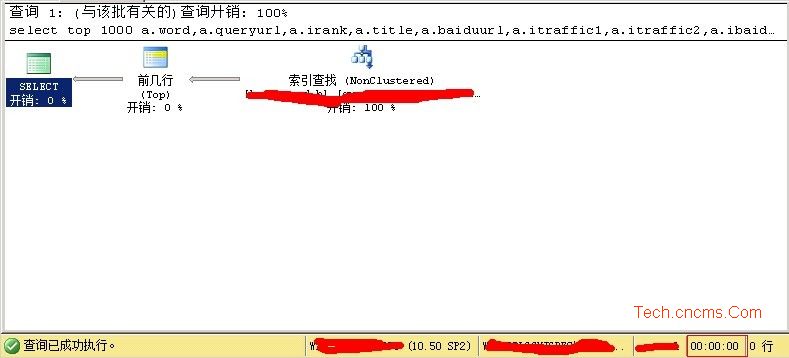
這裡拿以上這個sql語句來分析,我們該如何建立索引。索引建立包括字段的先後順序,字段的排序方法,include項都很重要,任何一個弄錯,都不能達到好的優化效果。
1.我們肯定需要建立一個組合索引。那麼應該組合字段用哪幾個呢?這裡我的組合字段是:queryurl(這個字段第一, 因為我們最先是根據這個字段進行篩選的)、ibaiduindex、irank
2.這裡要注意下,因為我的固定排序就是ibaiduindex desc,irank asc,所以字段的排列順序應該是:queryurl,ibaiduindex,irank。同時排序的類別是:ibaiduindex desc ,irank asc。這裡我一開始沒注意,ibaiduindex的排序是asc,結果發現執行上面那個SQL語句仍然需要2秒。
3.索引包含項,也很重要,如果不用包含項,索引查找到主鍵後, 還要根據主鍵去查找其他字段。所以我們需要設置索引包含性列,把除掉索引字段中剩余的其他字段都加進去。
優化後的效果就如上面的執行計劃圖所示,一次非聚集索引查找,就找到我們的數據,而且都不需要排序耗時,因為我們的索引已經按照順序排列好了。當然,這裡要說明下,索引包含確實好用,但是代價就是磁盤的空間。加了索引包含項,數據庫空間增加了幾十個G。



