萬盛學電腦網 >> 數據庫 >> mysql教程 >> 如何實現同步數據庫的數據一致性
如何實現同步數據庫的數據一致性
背景

最近,@阿裡正祥(陽老師)發了上面的一條微博,誰知一石激起千層浪,國內各路數據庫領域的朋友在此條微博上發散出無數新的話題,爭吵有之,激辯有之,抨擊有之,不一而足。總體來說,大家重點關注其中的一點:
在不使用共享存儲的情況下,傳統RDBMS(例如:Oracle/MySQL/PostgreSQL等),能否做到在主庫出問題時的數據零丟失。
這個話題被引爆之後,我們團隊內部也經過了激烈的辯論,多方各執一詞。辯論的過程中,差點就重現了烏克蘭議會時場景…

慶幸的是,在我的鐵腕統治之下,同學們還是保持著只關注技術,就事論事的撕逼氛圍,沒有上升到相互人身攻擊的層次。激辯的結果,確實是收獲滿滿,當時我就立即發了一條微博,宣洩一下自己愉悅的心情J
微博發出之後,也有一些朋友回復是否可以將激辯的內容寫出來,獨樂樂不如眾樂樂。我一想也對,強數據同步,數據一致性,性能,分區可用性,Paxos,Raft,CAP等一系列知識,我也是第一次能夠較好的組織起來,寫下來,一來可以加深自己的印象,二來也可以再多混一點虛名,何樂而不為J
這篇博客文章接下來的部分,將跳出任何一種數據庫,從原理的角度上來分析下面的幾個問題:
問題一:數據一致性。在不使用共享存儲的情況下,傳統RDBMS(例如:Oracle/MySQL/PostgreSQL等),能否做到在主庫出問題時的數據零丟失。
問題二:分區可用性。有多個副本的數據庫,怎麼在出現各種問題時保證系統的持續可用?
問題三:性能。不使用共享存儲的RDBMS,為了保證多個副本間的數據一致性,是否會損失性能?如何將性能的損失降到最低?
問題四:一個極端場景的分析。
問題一:數據一致性
問:脫離了共享存儲,傳統關系型數據庫就無法做到主備強一致嗎?
答:我的答案,是No。哪怕不用共享存儲,任何數據庫,也都可以做到主備數據的強一致。Oracle如此,MySQL如此,PostgreSQL如此,OceanBase也如此。
如何實現主備強一致?大家都知道數據庫中最重要的一個技術:WAL(Write-Ahead-Logging)。更新操作寫日志(Oracle Redo Log,MySQL Binlog等),事務提交時,保證將事務產生的日志先刷到磁盤上,保證整個事務的更新操作數據不丟失。那實現數據庫主備數據強一致的方法也很簡單:
事務提交的時候,同時發起兩個寫日志操作,一個是將日志寫到本地磁盤的操作,另一個是將日志同步到備庫並且確保落盤的操作;
主庫此時等待兩個操作全部成功返回之後,才返回給應用方,事務提交成功;
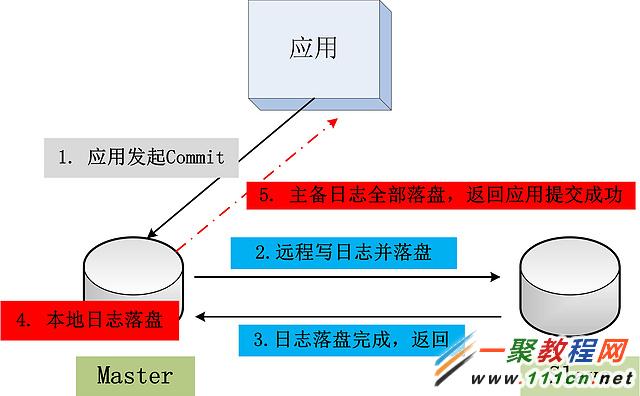
整個事務提交操作的邏輯,如下圖所示:
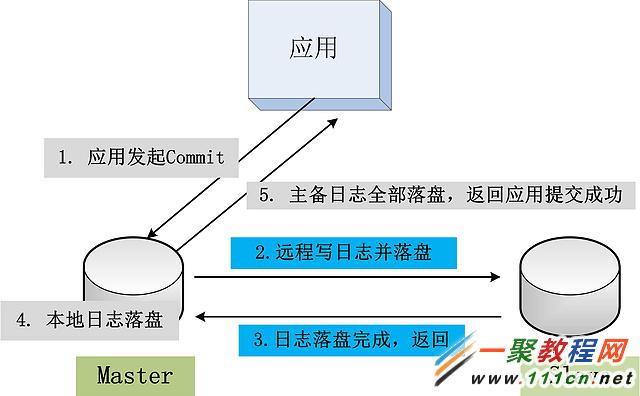
上圖所示,由於事務提交操作返回給應用時,事務產生的日志在主備兩個數據庫上都已經存在了,強同步。因此,此時主庫Crash的話,備庫提供服務,其數據與主庫是一致的,沒有任何事務的數據丟失問題。主備數據強一致實現。用過Oracle的朋友,應該都知道Oracle的Data Guard,可工作在 最大性能,最大可用,最大保護 三種模式下,其中第三種 最大保護 模式,采用的就是上圖中的基本思路。
實現數據的強同步實現之後,接下來到了考慮可用性問題。現在已經有主備兩個數據完全一致的數據庫,備庫存在的主要意義,就是在主庫出故障時,能夠接管應用的請求,確保整個數據庫能夠持續的提供服務:主庫Crash,備庫提升為主庫,對外提供服務。此時,又涉及到一個決策的問題,主備切換這個操作誰來做?人當然可以做,接收到主庫崩潰的報警,手動將備庫切換為主庫。但是,手動的效率是低下的,更別提數據庫可能會隨時崩潰,全部讓人來處理,也不夠厚道。一個HA(High Availability)檢測工具應運而生:HA工具一般部署在第三台服務器上,同時連接主備,當其檢測到主庫無法連接,就切換備庫,很簡單的處理邏輯,如下圖所示:
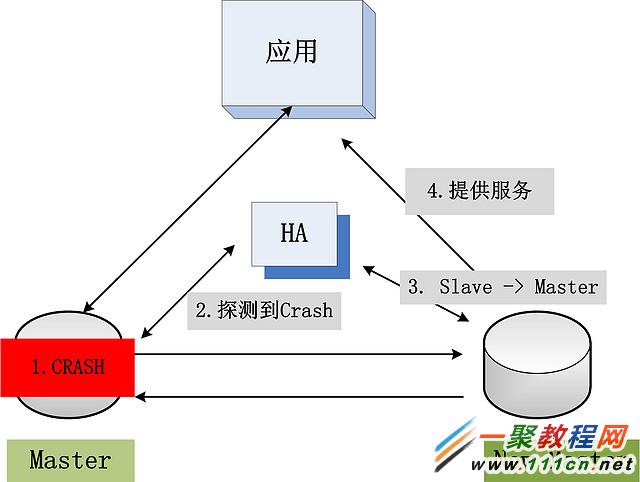
HA軟件與主備同時連接,並且有定時的心跳檢測。主庫Crash後,HA探測到,發起一個將備庫提升為主庫的操作(修改備庫的VIP或者是DNS,可能還需要將備庫激活等一系列操作),新的主庫提供對外服務。此時,由於主備的數據是通過日志強同步的,因此並沒有數據丟失,數據一致性得到了保障。
有了基於日志的數據強同步,有了主備自動切換的HA軟件,是不是就一切萬事大吉了?我很想說是,確實這個架構已經能夠解決90%以上的問題,但是這個架構在某些情況下,也埋下了幾個比較大的問題。
首先,一個一目了然的問題,主庫Crash,備庫提升為主庫之後,此時的數據庫是一個單點,原主庫重啟的這段時間,單點問題一直存在。如果這個時候,新的存儲再次Crash,整個系統就處於不可用狀態。此問題,可以通過增加更多副本,更多備庫的方式解決,例如3副本(一主兩備),此處略過不表。
其次,在主備環境下,處理主庫掛的問題,算是比較簡單的,決策簡單:主庫Crash,切換備庫。但是,如果不是主庫Crash,而是網絡發生了一些問題,如下圖所示:
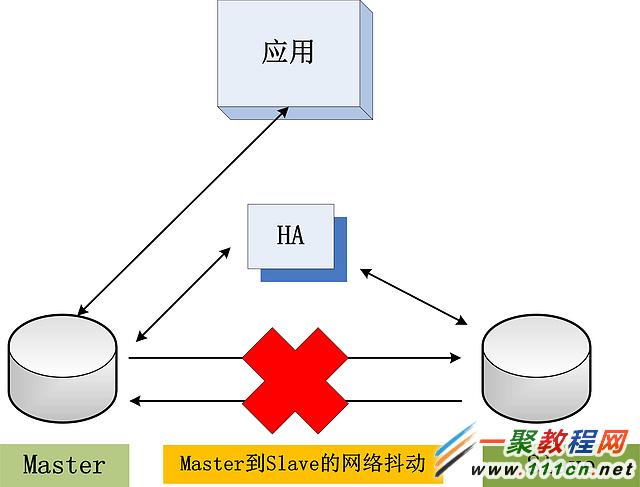
若Master與Slave之間的網絡出現問題,例如:斷網,網絡抖動等。此時數據庫應該怎麼辦?Master繼續提供服務?Slave沒有同步日志,會數據丟失。Master不提供服務?應用不可用。在Oracle中,如果設置為 最大可用 模式,則此時仍舊提供服務,允許數據不一致;如果設置為 最大保護 模式,則Master不提供服務。因此,在Oracle中,如果設置為 最大保護 模式,一般建議設置兩個或以上的Slave,任何一個Slave日志同步成功,Master就繼續提供服務,提供系統的可用性。
網絡問題不僅僅出現在Master和Slave之間,同樣也可能出現在HA與Master,HA與Slave之間。考慮下面的這種情況:
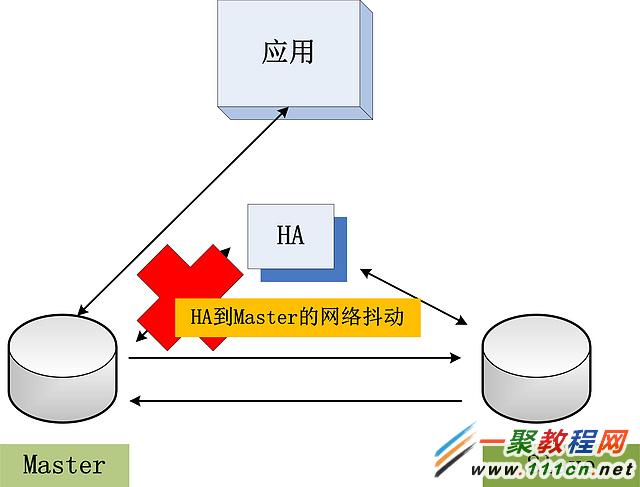
HA與Master之間的網絡出現問題,此時HA面臨兩個抉擇:
HA到Master之間的連接不通,認為主庫Crash。選擇將備庫提升為主庫。但實際上,只是HA到Master間的網絡有問題,原主庫是好的(沒有被降級為備庫,或者是關閉),仍舊能夠對外提供服務。新的主庫也可以對外提供服務。兩個主庫,產生雙寫問題,最為嚴重的問題。
HA到Master之間的連接不通,認為是網絡問題,主庫未Crash。HA選擇不做任何操作。但是,如果這時確實是主庫Crash了,HA不做操作,數據庫不對外提供服務。雙寫問題避免了,但是應用的可用性受到了影響。
最後,數據庫會出現問題,數據庫之間的網絡會出現問題,那麼再考慮一層,HA軟件本身也有可能出現問題。如下圖所示:
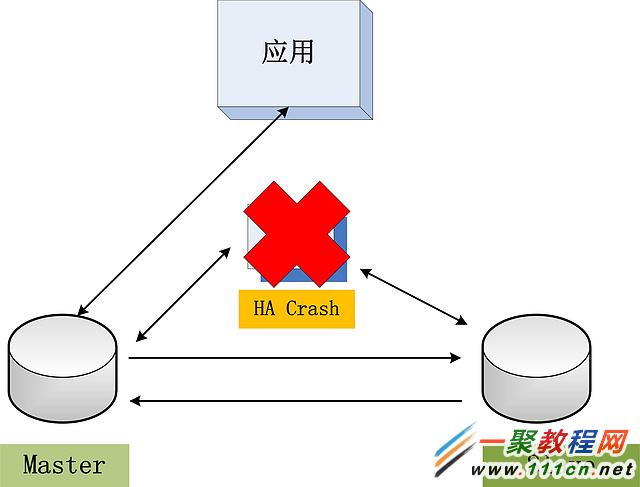
如果是HA軟件本身出現了問題,怎麼辦?我們通過部署HA,來保證數據庫系統在各種場景下的持續可用,但是HA本身的持續可用誰來保證?難道我們需要為HA做主備,然後再HA之上再做另一層HA?一層層加上去,子子孫孫無窮盡也 … …
其實,上面提到的這些問題,其實就是經典的分布式環境下的一致性問題(Consensus),近幾年比較火熱的Lamport老爺子的Paxos協議,Stanford大學最近發表的Raft協議,都是為了解決這一類問題。(對Raft協議感興趣的朋友,可以再看一篇Raft的動態演示PPT:Understandable Distributed Consensus)
問題二:分區可用性
前面,我們回答了第一個問題,數據庫如果不使用共享存儲,能否保證主備數據的強一致?答案是肯定的:可以。但是,通過前面的分析,我們又引出了第二個問題:如何保證數據庫在各種情況下的持續可用?至少前面提到的HA機制無法保證。那麼是否可以引入類似於Paxos,Raft這樣的分布式一致性協議,來解決上面提到的各種問題呢?
答案是可以的,我們可以通過引入類Paxos,Raft協議,來解決上面提到的各類問題,保證整個數據庫系統的持續可用。考慮仍舊是兩個數據庫組成的主備強一致系統,仍舊使用HA進行主備監控和切換,再回顧一下上一節新引入的兩個問題:
HA軟件自身的可用性如何保證?
如果HA軟件無法訪問主庫,那麼這時到底是主庫Crash了呢?還是HA軟件到主庫間的網絡出現問題了呢?如何確保不會同時出現兩個主庫,不會出現雙寫問題?
如何在解決上面兩個問題的同時,保證數據庫的持續可用?
為了解決這些問題,新的系統如下所示:
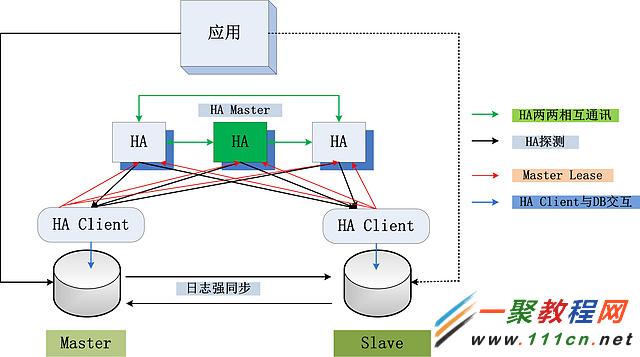
相對於之前的系統,可以看到這個系統的復雜性明顯增高,而且不止一成。數據庫仍舊是一主一備,數據強同步。但是除此之外,多了很多變化,這些變化包括:
數據庫上面分別部署了HA Client;
原來的一台HA主機,擴展到了3台HA主機。一台是HA Master,其余的為HA Participant;
HA主機與HA Client進行雙向通訊。HA主機需要探測HA Client所在的DB是否能夠提供服務,這個跟原有一致。但是,新增了一條HA Client到HA主機的Master Lease通訊。
這些變化,能夠解決上面的兩個問題嗎?讓我們一個一個來分析。首先是:HA軟件自身的可用性如何保證?
從一台HA主機,增加到3台HA主機,正是為了解決這個問題。HA服務,本身是無狀態的,3台HA主機,可以通過Paxos/Raft進行自動選主。選主的邏輯,我這裡就不做贅述,不是本文的重點,想詳細了解其實現的,可以參考互聯網上洋洋灑灑的關於Paxos/Raft的相關文章。總之,通過部署3台HA主機,並且引入Paxos/Raft協議,HA服務的高可用可以解決。HA軟件的可用性得到了保障。
第一個問題解決,再來看第二個問題:如何識別出當前是網絡故障,還是主庫Crash?如何保證任何情況下,數據庫有且只有一個主庫提供對外服務?
通過在數據庫服務器上部署HA Client,並且引入HA Client到HA Master的租約(Lease)機制,這第二個問題同樣可以得到完美的解決。所謂HA Client到HA Master的租約機制,就是說圖中的數據庫實例,不是永遠持有主庫(或者是備庫)的權利。當前主庫,處於主庫狀態的時間是有限制的,例如:10秒。每隔 10秒,HA Client必須向HA Master發起一個新的租約,續租它所在的數據庫的主庫狀態,只要保證每10秒收到一個來自HA Master同意續租的確認,當前主庫一直不會被降級為備庫。
第二個問題,可以細分為三個場景:
場景一:主庫Crash,但是主庫所在的服務器正常運行,HA Client運行正常
主庫Crash,HA Client正常運行。這種場景下,HA Client向HA Master發送一個放棄主庫租約的請求,HA Master收到請求,直接將備庫提升為主庫即可。原主庫起來之後,作為備庫運行。
場景二:主庫所在的主機Crash。(主庫和HA Client同時Crash)
此時,由於HA Client和主庫同時Crash,HA Master到HA Client間的通訊失敗。這個時候,HA Master還不能立即將備庫提升為主庫,因為區分不出場景二和接下來的場景三(網絡問題)。因此,HA Master會等待超過租約的時間(例如:12秒),如果租約時間之內仍舊沒有續租的消息。那麼HA Master將備庫提升為主庫,對外提供服務。原主庫所在的主機重啟之後,以備庫的狀態運行。
場景三:主庫正常,但是主庫到HA Master間的網絡出現問題
對於HA Master來說,是區分不出場景二和場景三的。因此,HA Master會以處理場景二同樣的邏輯處理場景三。等待超過租約的時間,沒有收到續租的消息,提升原備庫為主庫。但是在提升備庫之前,原主庫所在的HA Client需要做額外的一點事。原主庫HA Client發送給HA Master的續租請求,由於網絡問題,一直沒有得到響應,超過租約時間,主動將本地的主庫降級為備庫。如此一來,待HA Master將原備庫提升為主庫時,原來的主庫已經被HA Client降級為備庫。雙主的情況被杜絕,應用不可能產生雙寫。
通過以上三個場景的分析,問題二同樣在這個架構下被解決了。而解決問題二的過程中,系統最多需要等待租約設定的時間,如果租約設定為10秒,那麼出各種問題,數據庫停服的時間最多為10秒,基本上做到了持續可用。這個停服的時間,完全取決於租約的時間設置。
到這兒基本可以說,要實現一個持續可用(分區可用性保證),並且保證主備數據強一致的數據庫系統,是完全沒問題的。在現有數據庫系統上做改造,也是可以的。但是,如果考慮到實際的實現,這個復雜度是非常高的。數據庫的主備切換,是數據庫內部實現的,此處通過HA Master來提升主庫;通過HA Client來降級備庫;保證數據庫崩潰恢復後,恢復為備庫;通過HA Client實現主庫的租約機制;實現HA主機的可用性;所有的這些,在現有數據庫的基礎上實現,都有著相當的難度。能夠看到這兒,而且有興趣的朋友,可以針對此問題進行探討J
問題三:性能
數據一致性,通過日志的強同步,可以解決。分區可用性,在出現任何異常情況時仍舊保證系統的持續可用,可以在數據強同步的基礎上引入 Paxos/Raft等分布式一致性協議來解決,雖然這個目前沒有成熟的實現。接下來再讓我們來看看一個很多朋友都很感興趣的問題:如何在保證強同步的基礎上,同時保證高性能?回到我們本文的第一幅圖:
為了保證數據強同步,應用發起提交事務的請求時,必須將事務日志同步到Slave,並且落盤。相對於異步寫Slave,同步方式多了一次 Master到Slave的網絡交互,同時多了一次Slave上的磁盤sync操作。反應到應用層面,一次Commit的時間一定是增加了,具體增加了多少,要看主庫到備庫的網絡延時和備庫的磁盤性能。
為了提高性能,第一個很簡單的想法,就是部署多個Slave,只要有一個Slave的日志同步完成返回,加上本地的Master日志也已經落盤,提交操作就可以返回了。多個Slave的部署,對於消除瞬時的網絡抖動,非常有效果。在Oracle的官方建議中,如果使用最大保護模式,也建議部署多個 Slave,來最大限度的消除網絡抖動帶來的影響。如果部署兩個Slave,新的部署架構圖如下所示:
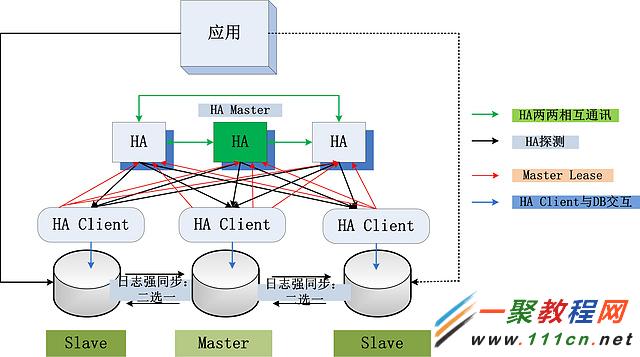
新增一個Slave,數據三副本。兩個Slave,只要有一個Slave日志同步完成,事務就可以提交,極大地減少了某一個網絡抖動造成的影響。增加了一個副本之後,還能夠解決當主庫Crash之後的數據安全性問題,哪怕主庫Crash,仍舊有兩個副本可以提供服務,不會形成單點。
但是,在引入數據三副本之後,也新引入了一個問題:主庫Crash的時候,到底選擇哪一個備庫作為新的主庫?當然,選主的權利仍舊是HA Master來行使,但是HA Master該如何選擇?這個問題的簡單解決可以使用下面的幾個判斷標准:
日志優先。兩個Slave,哪個Slave擁有最新的日志,則選擇這個Slave作為新的主庫。
主機層面排定優先級。如果兩個Slave同時擁有最新的日志,那麼該如何選擇?此時,選擇任何一個都是可以的。例如:可以根據Slave主機IP的大小進行選擇,選擇IP小的Slave作為新的主庫。同樣能夠解決問題。
新的主庫選擇出來之後,第一件需要做的事,就是將新的Master和剩余的一個Slave,進行日志的同步,保證二者日志達到一致狀態後,對應用提供服務。此時,三副本問題就退化為了兩副本問題,三副本帶來的防止網絡抖動的紅利消失,但是由於兩副本強同步,數據的可靠性以及一致性仍舊能夠得到保障。
當然,除了這一個簡單的三副本優化之外,還可以做其他更多的優化。優化的思路一般就是同步轉異步處理,例如事務提交寫日志操作;使用更細粒度的鎖;關鍵路徑可以采用無鎖編程等。
多副本強同步,做到極致,並不一定會導致系統的性能損失。極致應該是什麼樣子的?我的想法是:
對於單個事務來說,RT增加。其響應延時一定會增加(至少多一個網絡RT,多一次磁盤Sync);
對整個數據庫系統來說,吞吐量不變。遠程的網絡RT和磁盤Sync並不會消耗本地的CPU資源,本地CPU的開銷並未增大。只要是異步化做得好,整個系統的吞吐量,並不會由於引入強同步而降低。
問題四:一個極端場景的分析
意猶未盡,給仍舊在堅持看的朋友預留一個小小的作業。考慮下面這幅圖:如果用戶的提交操作,在圖中的第4步完成前,或者是第4步完成後第5步完成前,主庫崩潰。此時,備庫有最新的事務提交記錄,崩潰的主庫,可能有最新的提交記錄(第4步完成,第5步前崩潰),也可能沒有最新的記錄(第4步前崩潰),系統應該如何處理?
文章在博客上放出來之後,發現大家尤其對這最後一個問題最感興趣。我選擇了一些朋友針對這個問題發表的意見,僅供參考。
@淘寶丁奇
最後那個問題其實本質上跟主備無關。簡化一下是,在單庫場景下,db本地事務提交完成了,回復ack前crash,或者ack包到達前客戶端已經判定超時…所以客戶端只要沒有收到明確成功或失敗,臨界事務兩種狀態都是可以接受的。主備環境下只需要保證系統本身一致。
將丁奇意見用圖形化的方式表示出來,就是下面這幅圖:
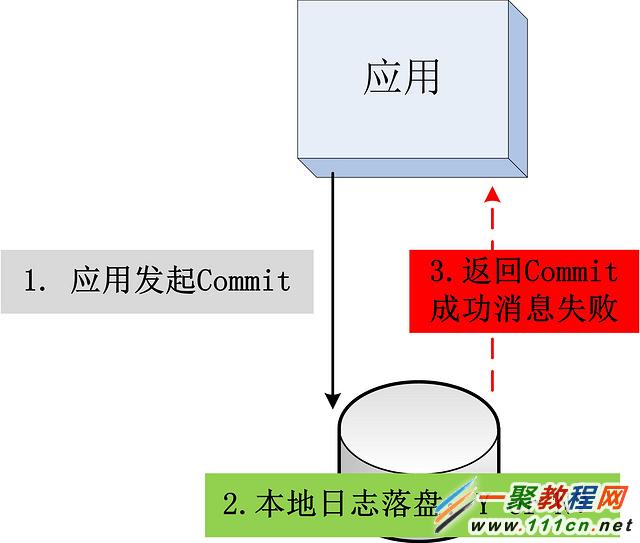
此圖,相對於問題四簡化了很多,數據庫沒有主備,只有一個單庫。應用發起Commit,在數據庫上執行日志落盤操作,但是在返回應用消息時失敗(網絡原因?超時?)。雖然架構簡化了,但是問題大同小異,此時應用並不能判斷出本次Commit是成功還是失敗,這個狀態,需要應用程序的出錯處理邏輯處理。
@ArthurHG
最後一個問題,關鍵是解決服務器端一致性的問題,可以讓master從slave同步,也可以讓slave回滾,因為客戶端沒有收到成功消息,所以怎麼處理都行。服務器端達成一致後,客戶端可以重新提交,為了實現冪等,每個transaction都分配唯一的ID;或者客戶端先查詢,然後根據結果再決定是否重新提交。
總結
洋洋灑灑寫了一堆廢話,最後做一個小小的總結:
能夠看到這裡的朋友,絕逼都是真愛,謝謝你們!!
各種主流關系型數據庫系統是否可以實現主備的強一致,是否可以保證不依賴於存儲的數據一致性?
可以。Oracle有,MySQL 5.7,阿裡雲RDS,網易RDS都有類似的功能。
目前各種關系型數據庫系統,能否在保證主備數據強一致的基礎上,提供系統的持續可用和高性能?
可以做,但是難度較大,目前主流關系型數據庫缺乏這個能力。



