萬盛學電腦網 >> 數據庫 >> mysql教程 >> mysql 查詢表字段有重復記錄個數的方法
mysql 查詢表字段有重復記錄個數的方法
情況一,直接查出重復
--查出表中有重復的id的記錄,並計算相同id的數量
select id,count(id) from @table group by id having(count(id)>1)
其中,group by id,是按id字段分組查詢:
select id,count(id) from @table group by id
可以得到各不同id的數量合計
having(count(id)>1)判斷數量大於1,也就是有重復id的記錄
情況二,按照重復出現的次數次數排序
利用Mysql中的 的聚合函數 count(*) 可以實現這個功能,例如需要查詢data表中name出現次數最多的記錄,可以先按照group by name分組,用count算出分組裡的條數,再按照count排序:
select name,count(*) from data group by name order by count(*) DESC limit 1
不加limit限制將返回按照name重復次數排列的數據
情況三,如果我們一張表有多個字段重復需要 查詢一張表某幾個字段 數據量重復次數最多的一條數據
查詢eye,nose,mouth三個字段中重復數據最多的,當每個字段的數據沒有重復的就查時間上最新的。結果是查出一條數據。(考慮一種情況是,比如eye字段中,a1和a2數量一樣多,也是查詢時間上最新的一條)
查詢結果:
eye nose mouth
a2 b2 c1
a2為eye字段中數量最多(與a1數量相同取時間最新的數據),b2為nose字段中最多的數據,c1為mouth字段中數據最多的
表結構
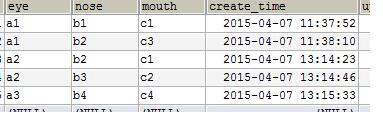
mysql> select * from face;
+----+-----+------+-------+---------------------+
| id | eye | nose | mouth | create_time |
+----+-----+------+-------+---------------------+
| 1 | a1 | b1 | c1 | 2015-04-07 20:40:11 |
| 2 | a1 | b2 | c3 | 2015-04-07 20:40:28 |
| 3 | a2 | b2 | c1 | 2015-04-07 20:40:52 |
| 4 | a2 | b3 | c2 | 2015-04-07 20:41:03 |
| 5 | a3 | b4 | c4 | 2015-04-07 20:41:19 |
+----+-----+------+-------+---------------------+
5 rows in set (0.00 sec)
mysql> select eye.eye, nose.nose, mouth.mouth from (select eye, create_time, count(*) from face group by eye order by count(*) desc, max(create_time) desc limit 1) as eye, (select nose, create_time, count(*) from face group by nose order by count(*) desc, max(create_time) desc limit 1) as nose, (select mouth, create_time, count(*) from face group by mouth order by count(*) desc, max(create_time) desc limit 1) as mouth;
+-----+------+-------+
| eye | nose | mouth |
+-----+------+-------+
| a2 | b2 | c1 |
+-----+------+-------+
1 row in set (0.01 sec)
看了下一樓回復的子查詢,在處理數量一樣,選時間最新的上有點小問題。這就是上面我加入max(create_time)的原因。不用max,返回的時間都是第一條記錄的。處理不了這種情況:a2第二條記錄的時間大於a1兩條記錄的時間。但是a1第一條記錄的時間大於a2第一條記錄的時間
注意返回時間:
有max得情況:
mysql> select eye, create_time, count(*) from face group by eye order by count(*) desc, max(create_time) desc limit 1;
+-----+---------------------+----------+
| eye | max(create_time) | count(*) |
+-----+---------------------+----------+
| a2 | 2015-04-07 20:41:03 | 2 |
+-----+---------------------+----------+
1 row in set (0.00 sec)
沒有max的情況:
mysql> select eye, create_time, count(*) from face group by eye order by count(*) desc, create_time desc limit 1;
+-----+---------------------+----------+
| eye | create_time | count(*) |
+-----+---------------------+----------+
| a2 | 2015-04-07 20:40:52 | 2 |
+-----+---------------------+----------+
1 row in set (0.00 sec)
注:max放在order by 後面。



