對於mysql數據庫我們今天就一起來看這篇關於MySQL 性能優化:性能提升 50%,延遲降低 60%的一個配置吧,具體的細節如下文介紹. 當我進入 Pinterest 時,我的頭三個星期是在本部度過的,在那裡最新工程把解決生產問題的成果應用到了整個軟件棧中。在本部,我們通過構建 Pinterest 來學習 Pinterest 是怎樣被構建的,並且,僅僅在幾天裡就提交代碼、做出有意義的貢獻也不是不常見。在 Pinterest ,新進來的工程師可以靈活地選擇參加哪個組,而且作為在本部工作經歷的一部分,編寫不同部分的代碼可以有助於做出這個選擇。本部的人通常會做不同的項目,而我的項目則是深入研究 MySQL 的性能優化。
Pinterest, MySQL 和 AWS,我的天!
我們的 MySQL 完全運行在 AWS 中。盡管使用了相當高性能的實例類型(配備 SSD RAID-0 陣列),和相當簡單的工作負載(很多基於主鍵或簡單范圍的單點查詢),峰值大約 2000 QPS,我們還是無法達到期望的 IO 性能水平。
寫 IOPS 一旦超過800,就會導致無法接受的延遲和復制滯後。復制滯後或者從庫的讀性能不足減慢 ETL 和批處理任務,依靠這些批處理任務的任何小組都會受到負面影響。唯一可行的選項是要麼選擇一個更大的實例,這樣會使我們的開銷翻倍、消除我們的效率,或者找辦法使現存的系統運行地更好。
我從我的同事 Rob Wultsch 那接手了這個項目,他已做出很重要的發現:當在 AWS 的 SSD 上運行時,Linux內核版本非常重要。Ubuntu 12.04 攜帶的默認 3.2 版本沒有減少開銷, AWS 推薦的最低 3.8 版本也沒有(盡管 3.8 仍比 3.2 快了兩倍多)。在一個 i2.2xlarge(雙SSD RAID-0 陣列)實例、3.2 內核版本上運行 sysbench 勉強在 16 K 隨機寫時達到 100 MB/sec。將內核升級至 3.8 會使我們在同樣的測試上達到 350 MB/sec,但這比期望值還是差了很多。看到這樣一個簡單的改變引起這樣的提升,為我們揭示了許多新的關於低效和差的配置選項的問題和猜想:我們能否從一個更新的內核上獲得更好的性能?我們應該改變 OS 級別的其他設置嗎?有沒有優化可以在 my.conf 中找到?我們怎樣能使 MySQL 運行地更快?
在尋找答案中,我設計了 60 個基本不同的 sysbench 文件 IO 測試配置,配合不同的內核、文件系統、掛載選項和 RAID 塊大小。一旦從這些實驗中選取了最佳配置,我又運行另外 20 個左右的 sysbench OLTP ,使用其他的系統配置。基本的測試方法在所有的測試中是相同的:運行測試一個小時,每隔 1 秒收集數據,然後考慮緩存熱身時間去掉開始的 600 秒的數據,最後處理剩下的數據。識別出最優配置後,我們重新構建了我們最大的、最重要的服務器,把這些改變放進了生產環境。
從 5000 QPS 到 26000 QPS : 擴展 MySQL 性能,無需擴展硬件
讓我們看看這些改變對一些基本的 sysbench OLTP 測試的影響,我們在 16 線程、 32 線程和幾個不同的配置下衡量 p99 響應時間和吞吐量兩個指標來看看效果。
這裡是每種數字代表的含義:
- CURRENT : 3.2 內核和標准的 MySQL 配置
- STOCK:3.18 內核和標准的 MySQL 配置
- KERNEL:3.18 內核和少量的 IO/內存 sysctl 微調
- MySQL:3.18 內核和優化過的 MySQL 配置
- KERN + MySQL:3.18 內核和 #3、#4 中的微調
- KERN + JE::3.18內核和 #3 中的微調和 jemalloc
- MySQL + JE:3.18 內核和 #4 中的 MySQL 配置和 jemalloc
- ALL:3.18 內核和 #3,#4 和 jemalloc

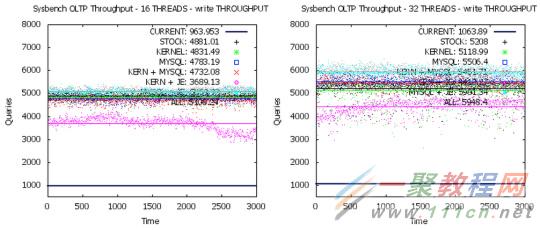
當我們啟用所有的優化後,我們發現在 16 和 32 線程下取得了大概 500% 多的讀寫吞吐量,同時在讀寫兩個方向上降低了 500 ms 的 p99 延遲。在讀方面,我們從大概 4100 – 4600 QPS 達到 22000 – 25000以上,分值取決於並發數。在寫方面,我們從大概 1000 QPS 達到 5100 – 6000 QPS。這些是在僅僅通過一些簡單改變獲得的巨大增長空間和性能提升。
當然,所有這些人工基准測試如果不能轉換成實際成果,都是沒有意義的。下圖展示了從客戶端和服務端的角度看,我們主要集群上的延遲,時間跨度為從升級前幾天到升級後幾天。這個過程花了一個星期才完成。

紅線表示客戶端感覺到的延遲,綠線表示服務端測到的延遲。從客戶端看,p99 延遲從一個波動較大、有時超過 100 ms 的 15 – 35 ms 降至相當平穩的 15 ms、有時會有 80 ms 或更低的異常值。服務端測量的延遲也從波動較大的 5 – 15 ms降至基本平穩的 5 ms,其中每天會有一個由系統維護引起的 18 ms 的尖值。此外,從年初起,我們的高峰吞吐量增加了 50%,所以我們不僅在處理相當大的負載(仍然在我們估計的容量裡),同時我們還擁有更好、更可預計的吞吐量。而且,對於每個想睡個安穩覺的人而言的好消息是,與系統性能或通用服務器負載相關的換頁事件從三月的 300 降至四月和五月兩個月加起來的幾個。



