萬盛學電腦網 >> 網絡編程 >> php編程 >> PHP函數rtrim()使用中的怪異現象分析
PHP函數rtrim()使用中的怪異現象分析
今天用rtrim()函數時遇到了一個奇怪的問題:
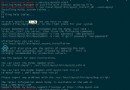
代碼如下 復制代碼
echortrim('<p></div>','</div>');// 輸出為 <p
echoltrim('www.jb51.net','www.');// 輸出為 jb51.net
以上的輸出結果有點出人意料,本來我想第一行應該輸出<p>,第二行會輸出jb51.net。
這個問題糾結了我好久,一直沒有找到原因,後來在手冊中找到了答案:
rtrim()是以字符為單位替換,而不是以字符串的。從右往左替換時</div>6個字符肯定會被替換掉的,再往左時遇到了>,因為>也包含在rtirm()的第二個參數的字符串(</div>)中,所以也被替換掉了,當再往左時遇到了p,這時p不包含在第二個參數的字符串中。所以替換停止,輸出了<p。
如果這樣理解的話,第二行的輸出結果就是在意料之中了。呵呵……手冊中已經寫的清清楚楚了。原文:
You can also specify the characters you want to strip, by means of the charlist parameter. Simply list all characters that you want to be stripped. With .. you can specify a range of characters。
由此可見,rtrim、ltrim與trim第二個參數是作為一組字符列表進行匹配操作的。這與我們以往認識的str_replace函數的替換操作不一樣。
php編程排行
程序編程推薦
相關文章
圖片文章



copyright © 萬盛學電腦網 all rights reserved