萬盛學電腦網 >> Linux教程 >> Linux系統進程管理介紹
Linux系統進程管理介紹
微軟系統的進程管理,無法就是打開任務管理器,查看進程、結束進程、或者創建進程。但是在Linux系統中進程管理是一件比較復雜的工作了。本文就來詳細介紹一下Linux系統進程管理。

普通調度算法
FCFS
First Come First Service。FIFO方式的調度策略,先來後到的服務方式。
這種方式的優勢是實現簡單,也是最容易想到的調度方案。但是有兩個重大問題:
1.對短進程的運行不利
短進程必須等到前面長進程執行完畢了之後才能運行,可能會等待較長時間。
2.對IO密集型運行不利
IO密集型比短進程還慘。還不容易排隊等到他運行了,結果沒運行一會兒就因為IO阻塞去了,等IO操作完畢了之後,還得重新排隊。
所以這個算法對IO密集型的進程運行效率是極其低下的。
RR
Round Robin。輪詢調度算法為每個進程分配固定的時間片,時間片用完了就必須重新到隊尾去排隊。
這樣的設計解決了FCFS的第一個問題,相對而言也部分解決了第2個問題。
但是對IO密集型進程依然解決得不太好,有一個優化的方案就是設計兩個隊列,將因為IO阻塞的進程單獨放一個隊列,在選擇下一個運行進行的時候對這個隊列的進程提權。
FCFS還有另外一個比較復雜的問題就是如何選擇時間片。時間片過長就退化成FCFS算法了,過短又會造成切換開銷太大。
Prediction
基於預測的算法。這類預測算法都是假設我們知道每個進程總共所需要的時間,以及IO占比信息。 上一頁12345下一頁共5頁
假設我們能收集到這些信息,可以有如下幾種調度算法:
1.最短運行時間優先
2.最短剩余時間優先
3.綜合已經運行時間和剩余時間來排序
但是在真實世界中,一般這個信息是無法預測的。即使是同一個進程,之前運行的情況對當前運行的進程也不一定有參考價值。比如cat程序,不同參數對運行時間影響很大。
Feedback
這個是基於Prediction來優化的。如果說Prediction是需要預測將來進程還需要多少資源的話,Feedback算法就是基於已經消耗了的資源來判斷優先級。
一般來說,也就是運行時間越長,優先級越低的調度算法。
Unix調度算法
老版調度算法
這是2.6版本之前的調度算法,該算法采用優化的RR算法,每個進程的優先級算法如下:
p(i) = base(i)+nice(i)+cpu(i)
其中base和nice值都是靜態固定的,可以由用戶指定的。
cpu是隨著進程占用CPU時間越長權重就越低的調整因子,該因子調整邏輯如下:
cpu(i) = cpu(i-1)/2
也就是每次進程被選中調度一遍之後,下次對應的cpu因子的值都會被除以2,降低下次運行的權重。
新版調度算法
內核2.6版本之後重寫了調度算法。也叫O(1)算法。
該算法針對普通進程,設置了100~139共40個優先級,進程屬於哪個優先級的計算跟老版調度算法類似。系統再存儲了一個位圖,每個位圖代表一個優先級是否有等待的進程。然後每次都選擇優先級最高的且有進程的那個隊列選取第一個進程來運行。
SMP的調度
對於多處理器的處理,跟上面的調度算法類似,只是在選擇出進程之後,需要再判斷一下給哪個CPU合適。
一般來說,考慮到CPU的本地cache,所以盡量將進程調度到之前運行的CPU上運行。當然,考慮到CPU本身的均衡性,所以肯定還是會有遷移的工作。 上一頁12 345下一頁共5頁
線程相關
用戶線程&內核線程
線程從一開始誕生就有兩個分類:用戶級線程 和 內核級線程。
我們在Linux上常見的是內核級線程, 即線程調度相關操作都在內核裡實現, 不太常見的是用戶級線程。
用戶級線程的優勢是:
1.線程切換成本低,不用內核操作
2.用戶可以自定義線程調度策略
3.跟操作系統無關,可以很快移植到另外一台機器上
但是用戶線程也有如下問題:
1.一個線程的阻塞會影響其他線程,因為操作系統看不到別的線程
2.不能很好的利用多核能力,因為操作系統會把一個內核進程放到一個CPU上
目前Linux上只使用內核級線程, Solaris上面兩者都提供。
線程切換
一個進程的上下文主要有如下幾個部分的信息構成:
1.程序計數器
2.寄存器信息
3.棧信息
一個進程切換的過程包含:
1.保存當前進程的上下文
2.將當前進程加入操作系統對應隊列
3.通過調度算法選擇另外一個進程
4.調整虛存映射
5.加載新進程的上下文
但是線程切換就不一樣了,之需要切換PC寄存器指向的代碼地址就好,其他操作都不用做,所以線程切換的成本比進程切換低多了。
互斥和同步
簡介
當多個進程需要對同一個資源進行訪問的時候, 為了避免同時使用這個資源造成的混亂, 所以需要考慮進程間的互斥。
典型的互斥實現方案如下:
方案介紹
中斷禁用
殺敵一千, 自損八百。雖然能實現互斥, 但是大大降低了處理器的執行效率。而且再多處理器體系結構中, 他還不能達到互斥
專用機器指令
往往是通過一個不可中斷的指令, 用於原子修改內存中的值, 常見的兩個指令是testset和exchange, 其對應的demo代碼如下圖。該方案的好處是實現簡單, 壞處是使用了忙等待, 可能出現饑餓, 可能死鎖, 需要操作系統層進行管理和避免。 上一頁123 45下一頁共5頁
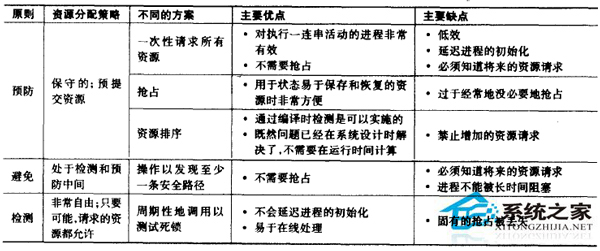
死鎖的避免
死鎖出現有4個必要條件:
1.互斥: 資源只能同時被一個進程使用
2.占有且等待: 一個進程在等待別的資源的時候, 將繼續占有其擁有的資源
3.非搶占: 不能強行搶占別人占有的資源
4.循環等待: 在滿足如上3個條件的情況下, 出現循環等待即出現死鎖
要避免死鎖也是從這4個條件上下手:
1.互斥: 這個是為了資源功能正常運轉, 無法避免
2.占有且等待: 讓進程一開始就申請所有資源才能運行。問題是效率低下, 進程可能要等待很長時間, 資源可能被控制很長時間, 程序也需要最開始就知道需要使用哪些資源;
3.非搶占: 根據進程優先級讓申請資源的進程釋放自己之前擁有的資源或者搶占別的進程的資源, 靠譜, 唯一的問題在於資源的使用不一定有那麼容易的保存和恢復(很多硬件不像處理器那樣可以隨意切換使用進程的)
4.循環等待: 給資源定義一個序列, 進程只能按照序列申請資源, 會導致進程執行效率大大降低, 所以主流做法是如下兩種
如上幾種避免辦法都有各種各樣的問題, 所以一般不采用, 現在采用最多的方案還是從第4點出發, 只不過不預先避免, 而是動態探測:
1.如果一個進程啟動或者新增資源需求會導致死鎖, 則不允許此分配
典型的算法如銀行家算法, 此方法的弊端是需要知道一個進程將來所需要占用的資源
2.允許所有請求, 周期性的進行檢測死鎖
動態檢測, 運行效率高, 但是如果出現死鎖頻率比較高, 則系統運行效率會比較低。
綜合所有的死鎖避免的方法的對比如下:
編程界面
多進程之間的互斥與同步方案有了如上提到的系列硬件支持之後, 就需要考慮操作系統對有並發編程的程序員們提供的編程界面了。
信號量
信號量是在內存中維護了一個int, 每次操作對該int進行++或者--。
對操作者提供了兩個接口:
1.semWait
該接口檢查int值, 如果該值大於0, 就將該值--, 並進入臨界區; 否則就阻塞檢測該值知道大於0;
2.



