萬盛學電腦網 >> 數據庫 >> mssql數據庫 >> 數據庫訪問性能優化
數據庫訪問性能優化
在網上有很多文章介紹數據庫優化知識,但是大部份文章只是對某個一個方面進行說明,而對於我們程序員來說這種介紹並不能很好的掌握優化知識,因為很多介紹只是對一些特定的場景優化的,所以反而有時會產生誤導或讓程序員感覺不明白其中的奧妙而對數據庫優化感覺很神秘。
很多程序員總是問如何學習數據庫優化,有沒有好的教材之類的問題。在書店也看到了許多數據庫優化的專業書籍,但是感覺更多是面向DBA或者是PL/SQL開發方面的知識,個人感覺不太適合普通程序員。而要想做到數據庫優化的高手,不是花幾周,幾個月就能達到的,這並不是因為數據庫優化有多高深,而是因為要做好優化一方面需要有非常好的技術功底,對操作系統、存儲硬件網絡、數據庫原理等方面有比較扎實的基礎知識,另一方面是需要花大量時間對特定的數據庫進行實踐測試與總結。
作為一個程序員,我們也許不清楚線上正式的服務器硬件配置,我們不可能像DBA那樣專業的對數據庫進行各種實踐測試與總結,但我們都應該非常了解我們SQL的業務邏輯,我們清楚SQL中訪問表及字段的數據情況,我們其實只關心我們的SQL是否能盡快返回結果。那程序員如何利用已知的知識進行數據庫優化?如何能快速定位SQL性能問題並找到正確的優化方向?
面對這些問題,筆者總結了一些面向程序員的基本優化法則,本文將結合實例來坦述數據庫開發的優化知識。
一、數據庫訪問優化法則簡介
要正確的優化SQL,我們需要快速定位能性的瓶頸點,也就是說快速找到我們SQL主要的開銷在哪裡?而大多數情況性能最慢的設備會是瓶頸點,如下載時網絡速度可能會是瓶頸點,本地復制文件時硬盤可能會是瓶頸點,為什麼這些一般的工作我們能快速確認瓶頸點呢,因為我們對這些慢速設備的性能數據有一些基本的認識,如網絡帶寬是2Mbps,硬盤是每分鐘7200轉等等。因此,為了快速找到SQL的性能瓶頸點,我們也需要了解我們計算機系統的硬件基本性能指標,下圖展示的當前主流計算機性能指標數據。

從圖上可以看到基本上每種設備都有兩個指標:
延時(響應時間):表示硬件的突發處理能力;
帶寬(吞吐量):代表硬件持續處理能力。
從上圖可以看出,計算機系統硬件性能從高到代依次為:
CPU——Cache(L1-L2-L3)——內存——SSD硬盤——網絡——硬盤
由於SSD硬盤還處於快速發展階段,所以本文的內容不涉及SSD相關應用系統。
根據數據庫知識,我們可以列出每種硬件主要的工作內容:
CPU及內存:緩存數據訪問、比較、排序、事務檢測、SQL解析、函數或邏輯運算;
網絡:結果數據傳輸、SQL請求、遠程數據庫訪問(dblink);
硬盤:數據訪問、數據寫入、日志記錄、大數據量排序、大表連接。
根據當前計算機硬件的基本性能指標及其在數據庫中主要操作內容,可以整理出如下圖所示的性能基本優化法則:

這個優化法則歸納為5個層次:
1、 減少數據訪問(減少磁盤訪問)
2、 返回更少數據(減少網絡傳輸或磁盤訪問)
3、 減少交互次數(減少網絡傳輸)
4、 減少服務器CPU開銷(減少CPU及內存開銷)
5、 利用更多資源(增加資源)
由於每一層優化法則都是解決其對應硬件的性能問題,所以帶來的性能提升比例也不一樣。傳統數據庫系統設計是也是盡可能對低速設備提供優化方法,因此針對低速設備問題的可優化手段也更多,優化成本也更低。我們任何一個SQL的性能優化都應該按這個規則由上到下來診斷問題並提出解決方案,而不應該首先想到的是增加資源解決問題。
以下是每個優化法則層級對應優化效果及成本經驗參考:

接下來,我們針對5種優化法則列舉常用的優化手段並結合實例分析。
二、Oracle數據庫兩個基本概念
數據塊(Block)
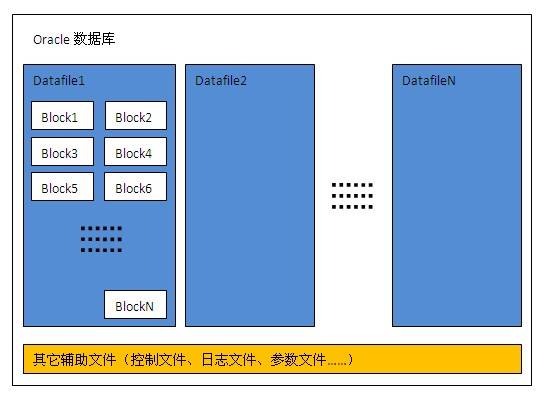
數據塊是數據庫中數據在磁盤中存儲的最小單位,也是一次IO訪問的最小單位,一個數據塊通常可以存儲多條記錄,數據塊大小是DBA在創建數據庫或表空間時指定,可指定為2K、4K、8K、16K或32K字節。下圖是一個Oracle數據庫典型的物理結構,一個數據庫可以包括多個數據文件,一個數據文件內又包含多個數據塊;
ROWID
ROWID是每條記錄在數據庫中的唯一標識,通過ROWID可以直接定位記錄到對應的文件號及數據塊位置。ROWID內容包括文件號、對像號、數據塊號、記錄槽號,如下圖所示:

三、數據庫訪問優化法則詳解
1、減少數據訪問
1.1、創建並使用正確的索引
數據庫索引的原理非常簡單,但在復雜的表中真正能正確使用索引的人很少,即使是專業的DBA也不一定能完全做到最優。
索引會大大增加表記錄的DML(INSERT,UPDATE,DELETE)開銷,正確的索引可以讓性能提升100,1000倍以上,不合理的索引也可能會讓性能下降100倍,因此在一個表中創建什麼樣的索引需要平衡各種業務需求。
索引常見問題:
索引有哪些種類?
常見的索引有B-TREE索引、位圖索引、全文索引,位圖索引一般用於數據倉庫應用,全文索引由於使用較少,這裡不深入介紹。B-TREE索引包括很多擴展類型,如組合索引、反向索引、函數索引等等,以下是B-TREE索引的簡單介紹:
B-TREE索引也稱為平衡樹索引(Balance Tree),它是一種按字段排好序的樹形目錄結構,主要用於提升查詢性能和唯一約束支持。B-TREE索引的內容包括根節點、分支節點、葉子節點。
葉子節點內容:索引字段內容+表記錄ROWID
根節點,分支節點內容:當一個數據塊中不能放下所有索引字段數據時,就會形成樹形的根節點或分支節點,根節點與分支節點保存了索引樹的順序及各層級間的引用關系。
一個普通的BTREE索引結構示意圖如下所示:

如果我們把一個表的內容認為是一本字典,那索引就相當於字典的目錄,如下圖所示:


圖中是一個字典按部首+筆劃數的目錄,相當於給字典建了一個按部首+筆劃的組合索引。
一個表中可以建多個索引,就如一本字典可以建多個目錄一樣(按拼音、筆劃、部首等等)。
一個索引也可以由多個字段組成,稱為組合索引,如上圖就是一個按部首+筆劃的組合目錄。
SQL什麼條件會使用索引?
當字段上建有索引時,通常以下情況會使用索引:
INDEX_COLUMN = ?
INDEX_COLUMN > ?
INDEX_COLUMN >= ?
INDEX_COLUMN < ?
INDEX_COLUMN <= ?
INDEX_COLUMN between ? and ?
INDEX_COLUMN in (?,?,...,?)
INDEX_COLUMN like ?||'%'(後導模糊查詢)
T1. INDEX_COLUMN=T2. COLUMN1(兩個表通過索引字段關聯)
SQL什麼條件不會使用索引?

我們一般在什麼字段上建索引?
這是一個非常復雜的話題,需要對業務及數據充分分析後再能得出結果。主鍵及外鍵通常都要有索引,其它需要建索引的字段應滿足以下條件:
1、字段出現在查詢條件中,並且查詢條件可以使用索引;
2、語句執行頻率高,一天會有幾千次以上;
3、通過字段條件可篩選的記錄集很小,那數據篩選比例是多少才適合?
這個沒有固定值,需要根據表數據量來



