萬盛學電腦網 >> 數據庫 >> mysql教程 >> mysql慢查詢日志分析
mysql慢查詢日志分析
第一步應該做的就是排查問題,找出瓶頸,所以,先從日志入手
開啟慢查詢日志
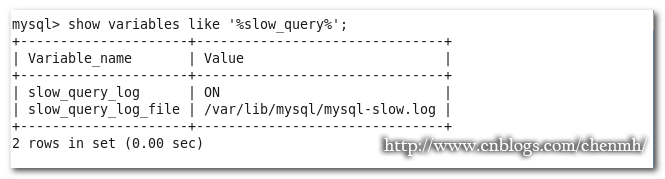
mysql>show variables like "%slow%";
查看慢查詢配置,沒有則在my.cnf中添加,如下
log-slow-queries = /data/mysqldata/slowquery.log #日志目錄
long_query_time = 1 #記錄下查詢時間查過1秒
log-queries-not-using-indexes #表示記錄下沒有使用索引的查詢
分析日志 – mysqldumpslow
分析日志,可用mysql提供的mysqldumpslow,使用很簡單,參數可–help查看
# -s:排序方式。c , t , l , r 表示記錄次數、時間、查詢時間的多少、返回的記錄數排序;
# ac , at , al , ar 表示相應的倒敘;
# -t:返回前面多少條的數據;
# -g:包含什麼,大小寫不敏感的;
使用實例:
mysqldumpslow -s r -t 10 /slowquery.log #slow記錄最多的10個語句
mysqldumpslow -s t -t 10 -g "left join" /slowquery.log #按照時間排序前10中含有"left join"的
mysql日志分析工具–mysqlsla
mysqlsla下載安裝:
wget http://hackmysql.com/scripts/mysqlsla-2.03.tar.gz
tar zvxf mysqlsla-2.03.tar.gz
cd mysqlsla-2.03
perl Makefile.PL
make
make install
mysqlsla /data/mysqldata/slow.log
使用實例:
mysqlsla /data/mysqldata/slow.log
# mysqlsla會自動判斷日志類型,為了方便可以建立一個配置文件”~/.mysqlsla”
# 在文件裡寫上:top=100,這樣會打印出前100條結果。
mysqlsla命令參數說明:
hackmysql.com推出的一款MySQL的日志分析工具
mysql
有一個功能就是可以log下來運行的比較慢的sql語句,默認是沒有這個log的,為了開啟這個功能,要修改my.cnf或者在mysql 啟動的時候加入一些參數。
如果在my.cnf裡面修改,需增加如下幾行
long_query_time = 10
log-slow-queries =
long_query_time 是指執行超過多久的sql會被log下來,這裡是10秒。
log-slow-queries 設置把日志 寫在那裡,為空的時候,系統會給慢查詢 日志賦予主機名,並被附加slow.log 如果設置了參數log-long-format,那麼所有沒有使用索引的查詢也將被記錄。在文件my.cnf或my.ini中加入下面這一行可以記錄這些查詢 這是一個有用的日志。它對於性能的影響不大(假設所有查詢都很快),並且強調了那些最需要注意的查詢(丟失了索引或索引沒有得到最佳應用)
# Time: 070927 8:08:52 # User@Host: root[root] @ [192.168.0.20] # Query_time: 372 Lock_time: 136 Rows_sent: 152 Rows_examined: 263630
select id, name from manager where id in (66,10135);
這是慢查詢 日志中的一條,用了372秒,鎖了136秒,返回152行,一共查了263630行
如果日志內容很多,用眼睛一條一條去看會累死,mysql 自帶了分析的工具,使用方法如下:
命令行下,進入mysql /bin 目錄,輸入mysqldumpslow –help 或--help 可以看到這個工具的參數,主要有
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (t, at, l, al, r, ar etc), 'at' is default
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql .server startup scrīpt)
-l don't subtract lock time from total time
-s ,是order 的順序,說明寫的不夠詳細,俺用下來,包括看了代碼,主要有
c,t,l,r 和ac,at,al,ar ,分別是按照query 次數,時間,lock 的時間和返回的記錄數來排序,前面加了a 的時倒敘
-t ,是top n 的意思,即為返回前面多少條的數據
-g ,後邊可以寫一個正則匹配模式,大小寫不敏感的
mysqldumpslow -s c -t 20 host-slow.log
mysqldumpslow -s r -t 20 host-slow.log
上述命令可以看出訪問次數最多的20 個sql 語句和返回記錄集最多的20 個sql 。
mysqldumpslow -t 10 -s t -g “left join” host-slow.log
這個是按照時間返回前10 條裡面含有左連接的sql 語句
整體來說, 功能非常強大. 數據報表,非常有利於分析慢查詢的原因, 包括執行頻率, 數據量, 查詢消耗等.
格式說明如下:
總查詢次數 (queries total), 去重後的sql數量 (unique)
輸出報表的內容排序(sorted by)
最重大的慢sql統計信息, 包括 平均執行時間, 等待鎖時間, 結果行的總數, 掃描的行總數.
Count, sql的執行次數及占總的slow log數量的百分比.
Time, 執行時間, 包括總時間, 平均時間, 最小, 最大時間, 時間占到總慢sql時間的百分比.
95% of Time, 去除最快和最慢的sql, 覆蓋率占95%的sql的執行時間.
Lock Time, 等待鎖的時間.
95% of Lock , 95%的慢sql等待鎖時間.
Rows sent, 結果行統計數量, 包括平均, 最小, 最大數量.
Rows examined, 掃描的行數量.
Database, 屬於哪個數據庫
Users, 哪個用戶,IP, 占到所有用戶執行的sql百分比
Query abstract, 抽象後的sql語句
Query sample, sql語句
除了以上的輸出, 官方還提供了很多定制化參數, 是一款不可多得的好工具.