萬盛學電腦網 >> 數據庫 >> mysql教程 >> mysql中ON DUPLICATE KEY UPDATE語法分析
mysql中ON DUPLICATE KEY UPDATE語法分析
[ON DUPLICATE KEY UPDATE用武之地]
如果表裡沒有則insert,若有了則update就需要用到mysql ON DUPLICATE KEY UPDATE語法;就樣就可以在代碼裡少寫if語句來判斷了
在INSERT語句末尾指定了ON DUPLICATE KEY UPDATE,並且插入行後會導致在一個UNIQUE索引或PRIMARY KEY中出現重復值,則在出現重復值的行執行UPDATE;如果不會導致唯一值列重復的問題,則插入新行。
[實例講解]
表結構
CREATE TABLE `spk_goods` (
`gid` int(11) NOT NULL auto_increment COMMENT '貨物id',
`cid` int(11) NOT NULL COMMENT '所屬分類id',
`name` char(30) NOT NULL COMMENT '貨物名稱',
PRIMARY KEY (`gid`),
UNIQUE KEY `NewIndex1` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8
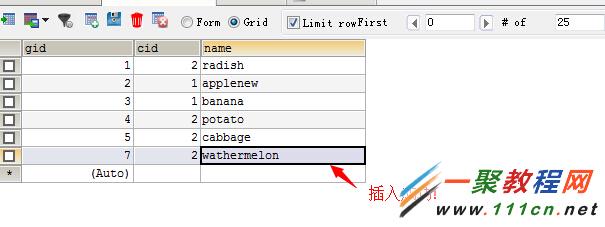
現有的表記錄
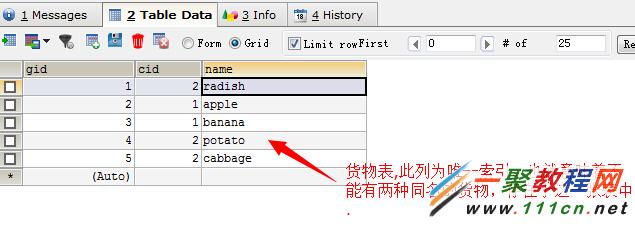
那麼問題來了,現有一個需求。要求插入一個新的貨物。若此貨物在表中已經存在,則在貨物名稱在以前的基礎上加一個後綴new;若以不存在此貨物,則插入到數據庫,用一條sql完成
測試一:插入表中已有的記錄
sql如下:
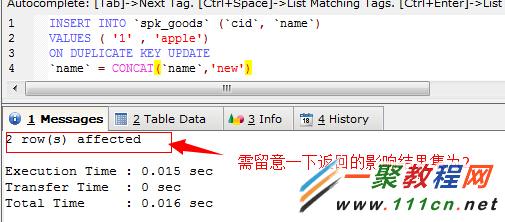
INSERT INTO `spk_goods` (`cid`, `name`)
VALUES ( '1' , 'apple')
ON DUPLICATE KEY UPDATE
`name` = CONCAT(`name`,'new')
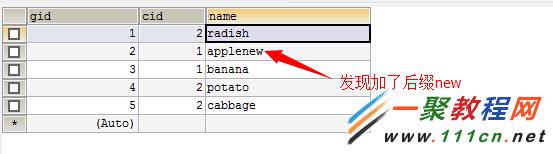 測試二:插入表中沒有的記錄
sql如下:
測試二:插入表中沒有的記錄
sql如下:
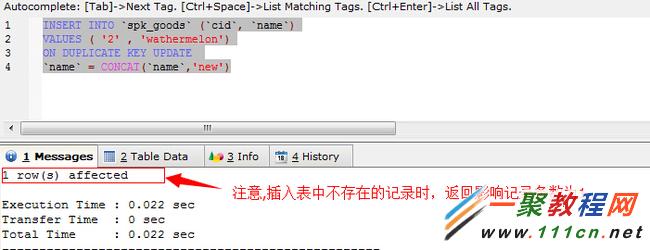
INSERT INTO `spk_goods` (`cid`, `name`)
VALUES ( '2' , 'wathermelon')
ON DUPLICATE KEY UPDATE
`name` = CONCAT(`name`,'new')
執行sql查看記錄變化
舉個例子,字段a被定義為UNIQUE,並且原數據庫表table中已存在記錄(2,2,9)和(3,2,1),如果插入記錄的a值與原有記錄重復,則更新原有記錄,否則插入新行:
復制代碼 代碼如下:
INSERT INTO TABLE (a,b,c) VALUES
(1,2,3),
(2,5,7),
(3,3,6),
(4,8,2)
ON DUPLICATE KEY UPDATE b=VALUES(b);
以上SQL語句的執行,發現(2,5,7)中的a與原有記錄(2,2,9)發生唯一值沖突,則執行ON DUPLICATE KEY UPDATE,將原有記錄(2,2,9)更新成(2,5,9),將(3,2,1)更新成(3,3,1),插入新記錄(1,2,3)和(4,8,2)



