萬盛學電腦網 >> 數據庫 >> mysql教程 >> MySQL集群億級數據量並發訪問解決方案測試
MySQL集群億級數據量並發訪問解決方案測試
測試過程如下:分別針對4種應用場景,從10、20、50、100個線程對MySQL展開測試。測試結果表明:對場景1)一般的並發訪問能夠滿足需求;對於場景2)和3)響應時間在分鐘級,分別處於1-3分鐘和10分鐘左右;對於場景4)則經常會拋出異常,並且以異常點為基准,其響應時間在30 分鐘左右。
測試環境
硬件環境:
Localhost:CPU: Intel Core I5, 主頻:3.10G, 內存:4G
MySQL集群:9台服務器
軟件環境:
Localhost: Win7,jdk 1.8
MySQL集群: MySQL5.6.25(社區版)
數據規模:
數據條目:一個月的股票數據,2億4千萬余條記錄,表結構為50個字段左右,具體內容見下面表結構。
表結構:
DROP TABLE IF EXISTS `TAQ_201504`;
CREATE TABLE `TAQ_201504` (
`SECCODE` varchar(6) NOT NULL,
`SECNAME` varchar(20) NOT NULL,
`TDATE` varchar(10) NOT NULL,
`TTIME` varchar(6) NOT NULL,
`LASTCLOSE` decimal(19,3) DEFAULT NULL,
`OP` decimal(19,3) DEFAULT NULL,
`CP` decimal(19,3) DEFAULT NULL,
`TQ` decimal(19,3) DEFAULT NULL,
`TM` decimal(19,3) DEFAULT NULL,
`TT` decimal(18,0) DEFAULT NULL,
`CQ` decimal(18,0) DEFAULT NULL,
`CM` decimal(19,3) DEFAULT NULL,
`CT` decimal(19,3) DEFAULT NULL,
`HIP` decimal(19,3) DEFAULT NULL,
`LOP` decimal(19,3) DEFAULT NULL,
`SYL1` decimal(19,3) DEFAULT NULL,
`SYL2` decimal(19,3) DEFAULT NULL,
`RF1` decimal(19,3) DEFAULT NULL,
`RF2` decimal(19,3) DEFAULT NULL,
`BS` varchar(18) DEFAULT NULL,
`S5` decimal(19,3) DEFAULT NULL,
`S4` decimal(19,3) DEFAULT NULL,
`S3` decimal(19,3) DEFAULT NULL,
`S2` decimal(19,3) DEFAULT NULL,
`S1` decimal(19,3) DEFAULT NULL,
`B1` decimal(19,3) DEFAULT NULL,
`B2` decimal(19,3) DEFAULT NULL,
`B3` decimal(19,3) DEFAULT NULL,
`B4` decimal(19,3) DEFAULT NULL,
`B5` decimal(19,3) DEFAULT NULL,
`SV5` decimal(20,0) DEFAULT NULL,
`SV4` decimal(20,0) DEFAULT NULL,
`SV3` decimal(15,0) DEFAULT NULL,
`SV2` decimal(15,0) DEFAULT NULL,
`SV1` decimal(15,0) DEFAULT NULL,
`BV1` decimal(15,0) DEFAULT NULL,
`BV2` decimal(15,0) DEFAULT NULL,
`BV3` decimal(15,0) DEFAULT NULL,
`BV4` decimal(15,0) DEFAULT NULL,
`BV5` decimal(15,0) DEFAULT NULL,
`BSRATIO` decimal(19,3) DEFAULT NULL,
`SPD` decimal(19,3) DEFAULT NULL,
`RPD` decimal(19,3) DEFAULT NULL,
`DEPTH1` decimal(20,3) DEFAULT NULL,
`DEPTH2` decimal(20,3) DEFAULT NULL,
`UNIX` bigint(20) DEFAULT NULL,
`MARKET` varchar(4) DEFAULT NULL,
KEY `SECCODE` (`SECCODE`,`TDATE`,`TTIME`)
) /*!50100 TABLESPACE ts_cloudstore STORAGE DISK */ ENGINE=ndbcluster DEFAULT CHARSET=utf8;
Table TAQ_201504
備注:`SECCODE`,`TDATE`,`TTIME`為組合索引,存於內存中。
性能測試
本文針對4中應用場景展開測試,分別從10、20、50、100個線程對MySQL展開測試。
1) 場景1
對某天的業務進行訪問查詢,即多個線程交互訪問如下示例:
select CP from TAQ_201504 where SECCODE='000001' AND TDATE = '20150401';
select CP from TAQ_201504 where SECCODE='000002' AND TDATE = '20150401';
select CP from TAQ_201504 where SECCODE='000003' AND TDATE = '20150401';
select CP from TAQ_201504 where SECCODE='000004' AND TDATE = '20150401';
select CP from TAQ_201504 where SECCODE='000005' AND TDATE = '20150401';
即每5個線程各自執行其中一條查詢,以10個線程舉例,則各自有2個線程會執行其中1條語句,其它線程與之類同,不再贅述。測試結果見表-1。
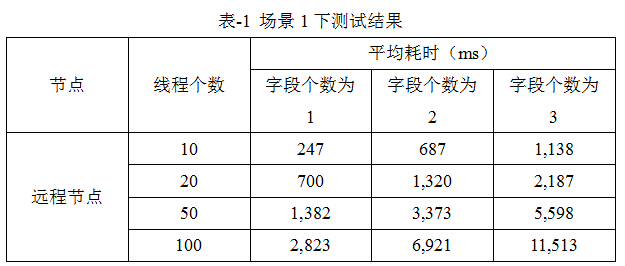
表-1結果表明:對於20-50個線程並發的場景下,按天查詢1-3個字段,數據響應時間大概在3s 以內。然而,在大量並發(100個線程)的場景下,數據顯示所需時間明顯增大。需要指出,雖然該測試能夠反映一些問題,但是增大多線程間切換所需的時間也是造成該時延增大的原因。
2) 場景2
對某個字段所處范圍,批量返回查詢結果,即多個線程並發訪問如下示例:
select CP from TAQ_201504 where SECCODE in ('000005','600010','000001','600100','600180','000002','000007','000008')
測試結果見表-2。

表-2結果表明:測試所需時間都已達到分鐘級。此外,對於表中異常情形,其症結在於,在單台機器上采用多線程測試,因此受限於本文測試的機器的存儲空間。本文作者認為,並非已達到MySQL數據庫的極限。
3)場景3
指定具體某一個字段,對全表進行查詢,即多線程並發訪問如下示例:
select cp from TAQ_201504 where ttime='145910'
測試結果見表-3。需要指出,本文未對50、100個線程展開測試,只是因為其耗時過長,故此,並未展開測試。
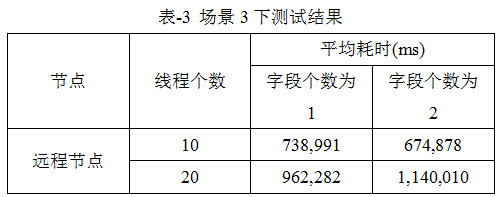
表-3結果表明:隨著字段個數增加,其處理耗時也逐漸增加,而且已達到分鐘級,而且基本達到10分鐘以上。
4)場景4
指定具體某些字段,對全表進行查詢,即多線程並發訪問如下示例:
select cp from TAQ_201504 where tdate='20150409' and ttime='145910'
測試結果見表-4。
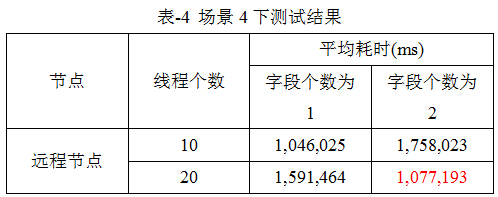
從表-4可知:在查詢中指定多個字段會增加查詢所需的時間。需要指出,由於上述SQL語句在查詢時,掃描數據庫花費的時間較多,導致Got error 4008 'Receive from NDB failed' from NDBCLUSTER,因此,表-4紅色部分,由於異常過早拋出,因此,在統計時間時存在偏差。本文作者認為,由於每次查詢差不多花費半個小時,造成數據訪問超時,很大程度上造成上述異常,此外,在單台機器上並發訪問該數據庫,線程間切換的時間也會對其造成一定的影響。
總結
從上述4中場景測試結果來看,對於查詢返回數據量相對較少時,多線程訪問MySQL是能夠滿足用戶需求的;當訪問數據量較大時,多線程訪問時能夠滿足連接需求的,但是具體向用戶進行展示時,其處理時間多在分鐘級,返回的字段、數據量越多,所耗的時間也逐漸增多。
億級數據的高並發通用搜索引擎架構設計
最近,我設計出了下列這套最新的搜索引擎架構,目前已經寫出“搜索查詢接口”和“索引更新接口”的beta版。經測試,在一台“奔騰四 3.6GHz 雙核CPU、2GB內存”的普通PC機,7000萬條索引記錄的條件下,“搜索查詢接口”平均查詢速度為0.0XX秒(查詢速度已經達到百度、谷歌、搜狗、中國雅虎等搜索引擎的水平,詳見文章末尾的“附2”),並且能夠支撐高達5000的並發連接;而“索引更新接口”進行數據分析、入隊列、返回信息給用戶的全過程,高達1500 Requests/Sec。
“隊列控制器”這一部分是核心,它要控制隊列讀取,更新MySQL主表與增量表,更新搜索引擎數據存儲層Tokyo Tyrant,准實時(1分鐘內)完成更新Sphinx增量索引,定期合並Sphinx索引。我預計在這周寫出beta版。

圖示說明:
1、搜索查詢接口:
①、Web應用服務器通過HTTP POST/GET方式,將搜索關鍵字等條件,傳遞給搜索引擎服務器的search.php接口;
②③、search.php通過Sphinx的API(我根據最新的Sphinx 0.9.9-rc1 API,改寫了一個C語言的PHP擴展sphinx.so),查詢Sphinx索引服務,取得滿足查詢條件的搜索引擎唯一ID(15位搜索唯一ID:前5 位類別ID+後10位原數據表主鍵ID)列表;
④⑤、search.php將這些ID號作為key,通過Memcache協議一次性從Tokyo Tyrant中mget取回ID號對應的文本數據。
⑥⑦、search.php將搜索結果集,按查詢條件,進行摘要和關鍵字高亮顯示處理,以JSON格式或XML格式返回給Web應用服務器。
2、索引更新接口:
⑴、Web應用服務器通過HTTP POST/GET方式,將要增加、刪除、更新的內容告知搜索服務器的update.php接口;
⑵、update.php將接收到的信息處理後,寫入TT高速隊列(我基於Tokyo Tyrant做的一個隊列系統);
注:這兩步的速度可達到1500次請求/秒以上,可應對6000萬PV的搜索索引更新調用。
3、搜索索引與數據存儲控制:
㈠、“隊列控制器”守護進程從TT高速隊列中循環讀取信息(每次50條,直到末尾);
㈡、“隊列控制器”將讀取出的信息寫入搜索引擎數據存儲層Tokyo Tyrant;
㈢、“隊列控制器”將讀取出的信息異步寫入MySQL主表(這張主表按500萬條記錄進行分區,僅作為數據永久性備份用);
㈣、“隊列控制器”將讀取出的信息寫入MySQL增量表;
㈤、“隊列控制器”在1分鐘內,觸發Sphinx更新增量索引,Sphinx的indexer會將MySQL增量表作為數據源,建立增量索引。Sphinx的增量索引和作為數據源的MySQL增量表成對應關系;
㈥、 “隊列控制器”每間隔3小時,短暫停止從TT高速隊列中讀取信息,並觸發Sphinx將增量索引合並入主索引(這個過程非常快),同時清空MySQL增量表(保證了MySQL增量表的記錄數始終只有幾千條至幾十萬條,大大加快Sphinx增量索引更新速度),然後恢復從TT高速隊列中取出數據,寫入 MySQL增量表。
本架構使用的開源軟件:
1、Sphinx 0.9.9-rc1
2、Tokyo Tyrant 1.1.9
3、MySQL 5.1.30
4、Nginx 0.7.22
5、PHP 5.2.6
本架構自主研發的程序:
1、搜索查詢接口(search.php)
2、索引更新接口(update.php)
3、隊列控制器
4、Sphinx 0.9.9-rc1 API的PHP擴展(sphinx.so)
5、基於Tokyo Tyrant的高速隊列系統
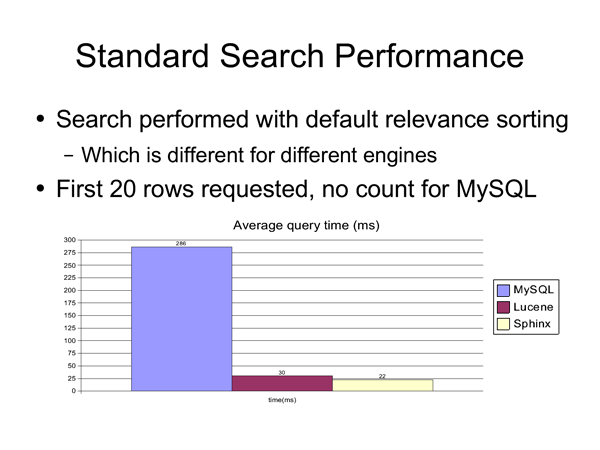
附1:MySQL FullText、Lucene搜索、Sphinx搜索的第三方對比結果:
1、查詢速度:
MySQL FullText最慢,Lucene、Sphinx查詢速度不相上下,Sphinx稍占優勢。
2、建索引速度:
Sphinx建索引速度是最快的,比Lucene快9倍以上。因此,Sphinx非常適合做准實時搜索引擎。



