萬盛學電腦網 >> 數據庫 >> mysql教程 >> 各版本MySQL並行復制的實現及優缺點
各版本MySQL並行復制的實現及優缺點
MySQL並行復制已經是老生常談,筆者從2010年開始就著手處理線上這個問題,剛開始兩三年也樂此不疲分享,現在再提這個話題本來是難免“炒冷飯”嫌疑。
最近觸發再談這個話題,是因為有些同學覺得“5.7的並行復制終於徹底解決了復制並發性問題”, 感覺還是有必要分析一下。大家都說沒有銀彈,但是又期待銀彈。。
既然要說5.7的並行復制,干脆順手把各個版本的並行復制都說明一下,也好有個對比。便是本次分享的初衷。
【背景】
一句話說完,因為這幾年太多這樣文章了, 就是MySQL一直以來的備庫復制都是單線程apply。
【解決基本思路】
改成多線程復制。
備庫有兩個線程與復制相關:io_thread 負責從主庫拿binlog並寫到relaylog, sql_thread 負責讀relaylog並執行。
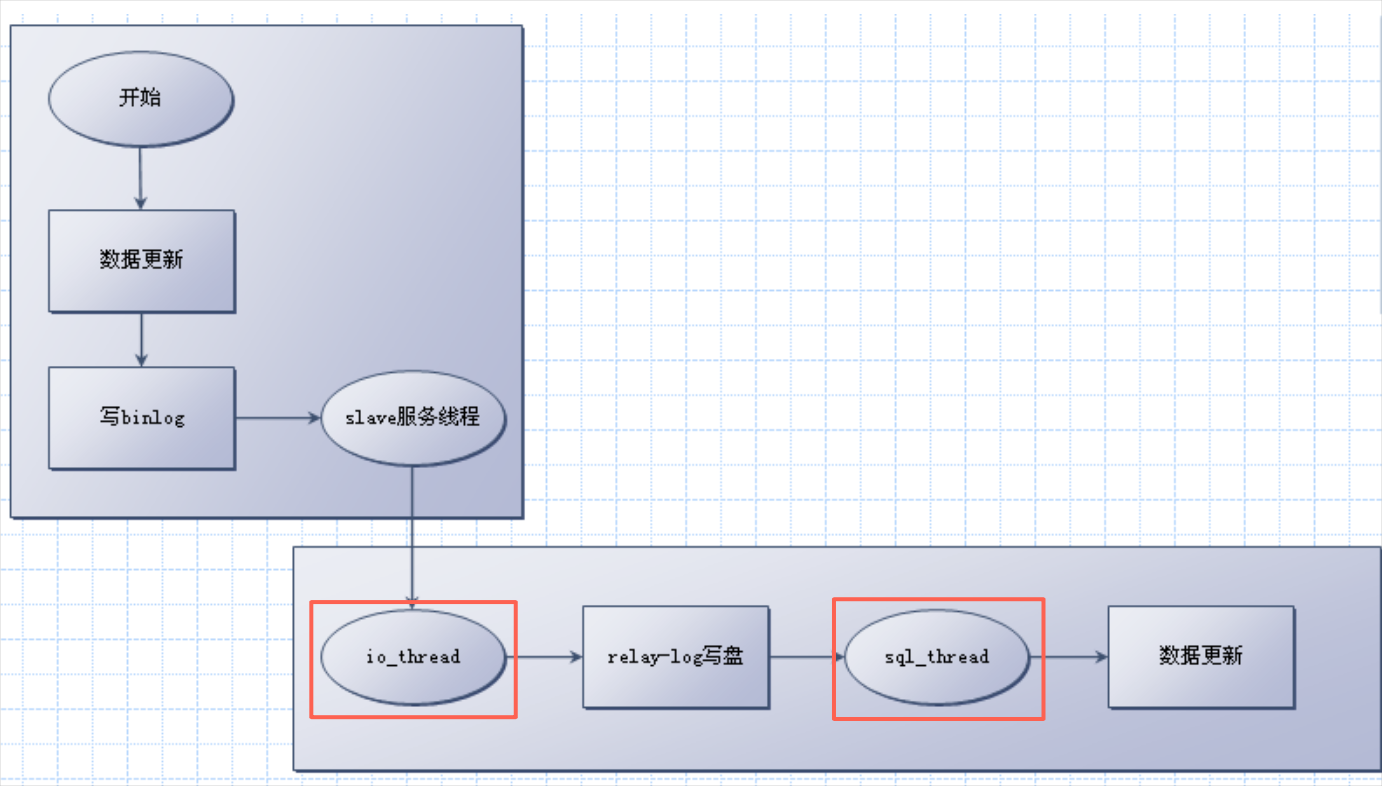
多線程的思路就是把sql_thread 變成分發線程,然後由一組worker_thread來負責執行。
幾乎所有的並行復制都是這個思路,有不同的,便是sql_thread 的分發策略。

而這些策略裡面又分成兩類:利用傳統binlog格式、修改binlog。
使用傳統的binlog格式的幾類,由於binlog裡面的信息就那些,因此只能按照粒度來分,也就是:按庫、按表、按行
另外有兩個策略是修改了binlog格式的,在binlog裡面增加了別的信息,用於體現提交分組。
下面我們分別介紹幾個並行復制的實現。
【5.5】
MySQL官方5.5是不支持並行復制的。但是在阿裡的業務需要並行復制的年份,還沒有官方版本支持,只好自己實現。而且從兼容性角度說,不修改binlog格式,所以采用的是利用傳統binlog格式的改造。
阿裡的版本支持兩種分發策略:按表和按行。
前情說明,由於MySQLbinlog日志還有用於別的系統的要求,因此阿裡的binlog格式都是row----這也給並行復制的實現減少了難度。
按表分發策略:row格式的binlog,每個DML前面都是有Table_map event的。因此很容易拿到庫名/表名。一個簡單的思路是,不同表的更新之間是不需要嚴格按照順序的。
因此按照表名hash,hash key是 庫名+表名,相同的表的更新放到同一個worker上。這樣就保證同一個表的更新順序,跟主庫上是一樣的。
應用場景:對於多表更新的場景效果特別好。缺點是反之的,若是熱點表更新,則本策略無效。而且由於hash表的維護,性能反而下降。
按行分發策略:row格式的binlog中,也不難拿到主鍵ID. 有同學說如果沒有主鍵怎麼辦,答案是"起開,現在誰還沒主鍵:)"。好吧,正經答案是沒有主鍵就不支持這個策略。
同樣的,我們認為不同行的更新,可以無序並發的。只要保證同一行的數據更新,在備庫上的順序與主庫上的相同即可。
因此按照主鍵id hash,所以這個hash key更長,必須是 庫名+表名+主鍵id。相同行的更新放到同一個worker上。
需要注意的是,上面的描述看上去都是對單個event的操作,實際上並不能!因為備庫可能接受讀,因此事務的原子性是要保證的,也就是說,對於涉及多個更新操作的事務,每次用於決策的不是一個hash key,而是一組。
應用場景:熱點表更新。缺點,hash key計算沖突的代價大。尤其是大事務,計算hash key的cpu消耗大,而且耗內存。這需要業務DBA做判斷得失。
【5.6】
官方的5.6支持的是按庫分發。有了上面的背景,大家就知道,這個feature出來以後,在中國並沒有什麼反響。
但是這個策略也要說也是有優點的:
1、對於可以按表分發的場景,可以通過將表遷到不同的庫,來應用此策略,有可操作性
2、速度更快,因為hash key就一個庫名
3、不要求binlog格式,大家知道不論是row還是statement格式,都是能夠輕松獲取庫名的。
所以並不是完全沒有用的。還是習慣問題。
【MariaDB】
MariaDB的並行復制策略看上去有好幾個選項,然而生產上可用的也就是默認值的 CONSERVATIVE。
由於maraiaDB支持多主復制,一個domain_id字段是用來標示事務來源的。如果來自於不同的主,自然可以並行(這個其實也是通用概念,還得業務DBA自己判斷)。
對於同一個主庫來的binlog,用commit_id 來決定分組。
想法是這樣的:在主庫上同時提交的事務設置成相同的commit_id。在備庫上apply時,相同的commit_id可以並行執行,因為這意味著這些事務之間是沒有行沖突的(否則不可能同時提交)。
這個思路跟最初從單線程改成多線程一樣,個人認為是劃時代的。
但是也並沒有解決了所有的問題。這個策略最怕的是,拖後腿事務。
設想一下這個場景,假設某個DB裡面正在作大量小更新事務(比如每個事務更新一行),這樣在備庫就並行得很歡樂。
然後突然,在同一個實例,另外一個庫下,或者同一個庫的另外一個跟目前的更新無關的表,突然有一個delte操作刪除了10w行。
delete事務在提交的時候,跟當時一起提交的事務都算同一個commit_id。假設為N.
之後的小事務更新提交組commit_id為N+1。
到備庫apply時,就會發現N這個組裡面,其他小事務都執行完了,線程進入空閒狀態,但是不能繼續執行N+1這個commit_id的事務,因為N裡面還有一個大事務沒有執行完成,這個我們認為是拖後腿的。
而基於傳統binlog格式的上面三個策略,反而沒有這個問題。只要是策略上能夠判斷不沖突,大事務自己有個線程跑,其他事務繼續並行。
【5.7】
MySQL官方5.7版本也是及時跟進,先引入了上述MariaDB的策略。當然從版權安全上,oracle是不會允許直接port代碼的。
實際上按組直接分段這個策略略顯粗暴。實際上事務提交並不是一個點,而是一個階段。至少我們可以分成:准備提交、提交中、提交完成。
這三個階段都是在事務已經完成了主要操作邏輯,進入commit狀態了。
同時進入“提交中”狀態的算同一個commit_id. 但是實際上,在任意時刻,處於”准備提交”的事務,與“提交中”的事務,也是可以並行的。但是明顯他們會被分成兩個不同的commit_id。
這意味著這個策略還有提升並發度的空間。
我們來看一下兩種策略的對比差別。
假設主庫有如下面示意圖的事務序列。每個事務提交過程看成兩個階段,prepare ... commit. 分別給不同的編號。其中commit對應的數字是自然數遞增,sequence_no。而prepare是對應的數字是X+1,這個X表示的是當前已經提交完成的sequence_no。
trx1 1…..2
trx2 1………….3
trx3 1…………………….4
trx4 2………………………….5
trx5 3………………………………..6
trx6 3………………………………………………7
trx7 6……………………..8
分析:
在MariaDB的策略裡面,並發執行序列如下:
trx1, trx2, trx3 ----group 1
trx4 -----group 2
trx 5, trx6 ----group 3
trx 7 ----group 4
每個group 執行完成後,下一個group 才可以開始。
完全執行完成的時間是每個group的最大事務時間之和,即 trx3 + trx4+trx6+trx7。
因此,如果某個group裡面有一個很大的事務,則整個序列的執行時間就會被拖久。
再來看5.7的改進策略:
雖然也是group1先啟動,但是在trx1完成後, trx4就可以開始執行;
同樣的,trx7可以在trx4執行完成後就開始執行,與trx5和trx6並發。
因此可以說上面這個例子中,備庫apply過程完全達到了主庫執行的並發度。
但是對於大事務,比如trx2 commit 非常久的情況,仍然存在拖後腿的問題。
補充:
MySQL 5.7並行復制原理
MySQL 5.7基於組提交的並行復制
MySQL 5.7才可稱為真正的並行復制,這其中最為主要的原因就是slave服務器的回放與主機是一致的即master服務器上是怎麼並行執行的slave上就怎樣進行並行回放。不再有庫的並行復制限制,對於二進制日志格式也無特殊的要求(基於庫的並行復制也沒有要求)。
從MySQL官方來看,其並行復制的原本計劃是支持表級的並行復制和行級的並行復制,行級的並行復制通過解析ROW格式的二進制日志的方式來完成,WL#4648。但是最終出現給小伙伴的確是在開發計劃中稱為:MTS: Prepared transactions slave parallel applier,可見:WL#6314。該並行復制的思想最早是由MariaDB的Kristain提出,並已在MariaDB 10中出現,相信很多選擇MariaDB的小伙伴最為看重的功能之一就是並行復制。
MySQL 5.7並行復制的思想簡單易懂,一言以蔽之:一個組提交的事務都是可以並行回放,因為這些事務都已進入到事務的prepare階段,則說明事務之間沒有任何沖突(否則就不可能提交)。
為了兼容MySQL 5.6基於庫的並行復制,5.7引入了新的變量slave-parallel-type,其可以配置的值有:
DATABASE:默認值,基於庫的並行復制方式
LOGICAL_CLOCK:基於組提交的並行復制方式
支持並行復制的GTID
如何知道事務是否在一組中,又是一個問題,因為原版的MySQL並沒有提供這樣的信息。在MySQL 5.7版本中,其設計方式是將組提交的信息存放在GTID中。那麼如果用戶沒有開啟GTID功能,即將參數gtid_mode設置為OFF呢?故MySQL 5.7又引入了稱之為Anonymous_Gtid的二進制日志event類型,如:
mysql> SHOW BINLOG EVENTS in 'mysql-bin.000006';
+------------------+-----+----------------+-----------+-------------+-----------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+----------------+-----------+-------------+-----------------------------------------------+
| mysql-bin.000006 | 4 | Format_desc | 88 | 123 | Server ver: 5.7.7-rc-debug-log, Binlog ver: 4 |
| mysql-bin.000006 | 123 | Previous_gtids | 88 | 194 | f11232f7-ff07-11e4-8fbb-00ff55e152c6:1-2 |
| mysql-bin.000006 | 194 | Anonymous_Gtid | 88 | 259 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| mysql-bin.000006 | 259 | Query | 88 | 330 | BEGIN |
| mysql-bin.000006 | 330 | Table_map | 88 | 373 | table_id: 108 (aaa.t) |
| mysql-bin.000006 | 373 | Write_rows | 88 | 413 | table_id: 108 flags: STMT_END_F |
.....
這意味著在MySQL 5.7版本中即使不開啟GTID,每個事務開始前也是會存在一個Anonymous_Gtid,而這GTID中就存在著組提交的信息。
LOGICAL_CLOCK
然而,通過上述的SHOW BINLOG EVENTS,我們並沒有發現有關組提交的任何信息。但是通過mysqlbinlog工具,用戶就能發現組提交的內部信息:
root@localhost:~# mysqlbinlog mysql-bin.0000006 | grep last_committed
#150520 14:23:11 server id 88 end_log_pos 259 CRC32 0x4ead9ad6 GTID last_committed=0 sequence_number=1
#150520 14:23:11 server id 88 end_log_pos 1483 CRC32 0xdf94bc85 GTID last_committed=0 sequence_number=2
#150520 14:23:11 server id 88 end_log_pos 2708 CRC32 0x0914697b GTID last_committed=0 sequence_number=3
#150520 14:23:11 server id 88 end_log_pos 3934 CRC32 0xd9cb4a43 GTID last_committed=0 sequence_number=4
#150520 14:23:11 server id 88 end_log_pos 5159 CRC32 0x06a6f531 GTID last_committed=0 sequence_number=5
#150520 14:23:11 server id 88 end_log_pos 6386 CRC32 0xd6cae930 GTID last_committed=0 sequence_number=6
#150520 14:23:11 server id 88 end_log_pos 7610 CRC32 0xa1ea531c GTID last_committed=6 sequence_number=7
...
可以發現較之原來的二進制日志內容多了last_committed和sequence_number,last_committed表示事務提交的時候,上次事務提交的編號,如果事務具有相同的last_committed,表示這些事務都在一組內,可以進行並行的回放。例如上述last_committed為0的事務有6個,表示組提交時提交了6個事務,而這6個事務在從機是可以進行並行回放的。
上述的last_committed和sequence_number代表的就是所謂的LOGICAL_CLOCK。先來看源碼中對於LOGICAL_CLOCK的定義:
class Logical_clock
{
private:
int64 state;
/*
Offset is subtracted from the actual "absolute time" value at
logging a replication event. That is the event holds logical
timestamps in the "relative" format. They are meaningful only in
the context of the current binlog.
The member is updated (incremented) per binary log rotation.
*/
int64 offset;
......
state是一個自增的值,offset在每次二進制日志發生rotate時更新,記錄發生rotate時的state值。其實state和offset記錄的是全局的計數值,而存在二進制日志中的僅是當前文件的相對值。使用LOGICAL_CLOCK的場景如下:
class MYSQL_BIN_LOG: public TC_LOG
{
...
public:
/* Committed transactions timestamp */
Logical_clock max_committed_transaction;
/* "Prepared" transactions timestamp */
Logical_clock transaction_counter;
...
可以看到在類MYSQL_BIN_LOG中定義了兩個Logical_clock的變量:
max_c ommitted_transaction:記錄上次組提交時的logical_clock,代表上述mysqlbinlog中的last_committed
transaction_counter:記錄當前組提交中各事務的logcial_clock,代表上述mysqlbinlog中的sequence_number
並行復制測試
下圖顯示了開啟MTS後,slave服務器的QPS。測試的工具是sysbench的單表全update測試,測試結果顯示在16個線程下的性能最好,從機的QPS可以達到25000以上,進一步增加並行執行的線程至32並沒有帶來更高的提升。而原單線程回放的QPS僅在4000左右,可見MySQL 5.7 MTS帶來的性能提升,而由於測試的是單表,所以MySQL 5.6的MTS機制則完全無能為力了。
mysql
mysql 5.7 並行復制
並行復制配置與調優
master_info_repository
開啟MTS功能後,務必將參數master_info_repostitory設置為TABLE,這樣性能可以有50%~80%的提升。這是因為並行復制開啟後對於元master.info這個文件的更新將會大幅提升,資源的競爭也會變大。在之前InnoSQL的版本中,添加了參數來控制刷新master.info這個文件的頻率,甚至可以不刷新這個文件。因為刷新這個文件是沒有必要的,即根據master-info.log這個文件恢復本身就是不可靠的。在MySQL 5.7中,Inside君推薦將master_info_repository設置為TABLE,來減小這部分的開銷。
slave_parallel_workers
若將slave_parallel_workers設置為0,則MySQL 5.7退化為原單線程復制,但將slave_parallel_workers設置為1,則SQL線程功能轉化為coordinator線程,但是只有1個worker線程進行回放,也是單線程復制。然而,這兩種性能卻又有一些的區別,因為多了一次coordinator線程的轉發,因此slave_parallel_workers=1的性能反而比0還要差,在Inside君的測試下還有20%左右的性能下降,如下圖所示:
mysql
mysql 5.7 並行復制
這裡其中引入了另一個問題,如果主機上的負載不大,那麼組提交的效率就不高,很有可能發生每組提交的事務數量僅有1個,那麼在從機的回放時,雖然開啟了並行復制,但會出現性能反而比原先的單線程還要差的現象,即延遲反而增大了。聰明的小伙伴們,有想過對這個進行優化嗎?
Enhanced Multi-Threaded Slave配置
說了這麼多,要開啟enhanced multi-threaded slave其實很簡單,只需根據如下設置:
# slave
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
並行復制監控
復制的監控依舊可以通過SHOW SLAVE STATUS\G,但是MySQL 5.7在performance_schema架構下多了以下這些元數據表,用戶可以更細力度的進行監控:
mysql> show tables like 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)
【小結】
按粒度區分的三個策略,粒度從粗到細是按庫、按表、按行。
這三個的對比中,並行度越來越大,額外損耗也是。無關大事務不會影響並發度。
按照commit_id 的兩個策略,適用范圍更廣,額外消耗也低。
5.7的改進策略並發性更優。但出現大事務會拖後腿。
另外,很重要的一點,5.7的策略目的是“模擬主庫並發”,所以對於主庫單線程更新是無加速作用的。而基於沖突的前三個策略,若滿足並發條件,會出現備庫比主庫執行速度快的情況。這種需求在搭備庫或者延遲復制的場景中可能觸發。
實際上策略的選擇取決於應用場景,這是架構師的工作之一。
PS:具體5.7的實現原理可參考我們團隊的@印風 同學的博客 http://mysqllover.com/?p=1370 (最後一個例子的case也從此摘錄)



