萬盛學電腦網 >> 數據庫 >> mysql教程 >> Mysql大指量插入數據時SQL語句的優化
Mysql大指量插入數據時SQL語句的優化
1) 對於Myisam類型的表,可以通過以下方式快速的導入大量的數據。
ALTER TABLE tblname DISABLE KEYS;
loading the data
ALTER TABLE tblname ENABLE KEYS;
這兩個命令用來打開或者關閉Myisam表非唯一索引的更新。在導入大量的數據到一個非空的Myisam表時,通過設置這兩個命令,可以提高導入的效率。對於導入大量數據到一個空的Myisam表,默認就是先導入數據然後才創建索引的,所以不用進行設置。
而對於Innodb類型的表,這種方式並不能提高導入數據的效率。
2) 對於Innodb類型的表,我們有以下幾種方式可以提高導入的效率:
因為Innodb類型的表是按照主鍵的順序保存的,所以將導入的數據按照主鍵的順序排列,可以有效的提高導入數據的效率。如果Innodb表沒有主鍵,那麼系統會默認創建一個內部列作為主鍵,所以如果可以給表創建一個主鍵,將可以利用這個優勢提高導入數據的效率。
在導入數據前執行SET UNIQUE_CHECKS=0,關閉唯一性校驗,在導入結束後執行SET UNIQUE_CHECKS=1,恢復唯一性校驗,可以提高導入的效率。
如果應用使用自動提交的方式,建議在導入前執行SET AUTOCOMMIT=0,關閉自動提交,導入結束後再執行SET AUTOCOMMIT=1,打開自動提交,也可以提高導入的效率。
經過對MySQL innodb的一些性能測試,發現一些可以提高insert效率的方法,供大家參考參考。
1. 一條SQL語句插入多條數據。
常用的插入語句如:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
修改成:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0), ('1', 'userid_1', 'content_1', 1);
修改後的插入操作能夠提高程序的插入效率。這裡第二種SQL執行效率高的主要原因是合並後日志量(MySQL的binlog和innodb的事務讓日志)減少了,降低日志刷盤的數據量和頻率,從而提高效率。通過合並SQL語句,同時也能減少SQL語句解析的次數,減少網絡傳輸的IO。
這裡提供一些測試對比數據,分別是進行單條數據的導入與轉化成一條SQL語句進行導入,分別測試1百、1千、1萬條數據記錄。
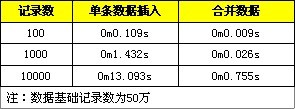
2. 在事務中進行插入處理。
把插入修改成:
START TRANSACTION;
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
...
COMMIT;
3. 數據有序插入。
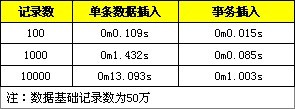
數據有序的插入是指插入記錄在主鍵上是有序排列,例如datetime是記錄的主鍵:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);
修改成:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);
由於數據庫插入時,需要維護索引數據,無序的記錄會增大維護索引的成本。我們可以參照innodb使用的B+tree索引,如果每次插入記錄都在索引的最後面,索引的定位效率很高,並且對索引調整較小;如果插入的記錄在索引中間,需要B+tree進行分裂合並等處理,會消耗比較多計算資源,並且插入記錄的索引定位效率會下降,數據量較大時會有頻繁的磁盤操作。
下面提供隨機數據與順序數據的性能對比,分別是記錄為1百、1千、1萬、10萬、100萬。
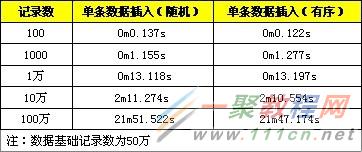
從測試結果來看,該優化方法的性能有所提高,但是提高並不是很明顯。
性能綜合測試:
這裡提供了同時使用上面三種方法進行INSERT效率優化的測試。
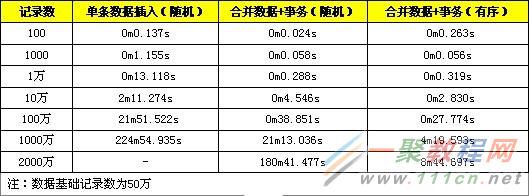
從測試結果可以看到,合並數據+事務的方法在較小數據量時,性能提高是很明顯的,數據量較大時(1千萬以上),性能會急劇下降,這是由於此時數據量超過了innodb_buffer的容量,每次定位索引涉及較多的磁盤讀寫操作,性能下降較快。而使用合並數據+事務+有序數據的方式在數據量達到千萬級以上表現依舊是良好,在數據量較大時,有序數據索引定位較為方便,不需要頻繁對磁盤進行讀寫操作,所以可以維持較高的性能。
注意事項:
1. SQL語句是有長度限制,在進行數據合並在同一SQL中務必不能超過SQL長度限制,通過max_allowed_packet配置可以修改,默認是1M,測試時修改為8M。
2. 事務需要控制大小,事務太大可能會影響執行的效率。MySQL有innodb_log_buffer_size配置項,超過這個值會把innodb的數據刷到磁盤中,這時,效率會有所下降。所以比較好的做法是,在數據達到這個這個值前進行事務提交。



