萬盛學電腦網 >> 媒體工具 >> 如何才能識別圖片中的文字
如何才能識別圖片中的文字
在日常的工作生活中,我們經常會遇到一些不能復制的網頁、文檔,或者需要將書籍上的文章錄入到電腦,這個時候大家都會十分的煩惱,因為手動輸入是一個非常大的工程,十分浪費大家的時間,另外,我們手動輸入的時候,經常會無意識的出現很多錯誤,針對這種情況,捷速OCR文字識別軟件就派上用場了,它可以幫助用戶解決文字識別的煩惱。下面小編就給大家分享一下使用捷速OCR文字識別軟件從圖片中提取文字的教程。
在使用捷速OCR文字識別軟件之前,我們先來了解一下軟件。捷速ocr文字識別軟件是一款知名的文字識別軟件,專門為用戶提供圖片文字識別服務,是一個帶有 PDF 文件處理功能的 OCR 軟件,它具有多種特色:
1.識別正確率高,識別速度快
2.具有有批量處理功能,避免了單個處理的麻煩
3.支持處理灰度、彩色、黑白三種色彩的BMP、TIF、JPG、PDF多種格式的圖像文件
4.支持多國家支持多國字符
5.可以識別和轉換幾乎所有打印的文檔類型和文件格式(如:JPG、GIF、PNG、BMP、TIF和PDF源文件、PDF掃描件)
6.無需“添加文件”,支持文件拖曳上傳
對於文字識別工具來說,圖片的明暗、清晰度對識別的效果都會有一定的影響,亮度選擇是否恰當直接關系到圖像的清晰度,而圖像的清晰度又直接影響後續的識別質量,因此必須根據稿件的實際質量來選擇亮度。所要達到的掃描質量為保證每個掃描漢字的圖像清晰,不能出現過濃或過淡。
下面大家可以開始我們的文字識別工作了。
准備工作:
首先我們可以到軟件的官網或是其他下載渠道將軟件下載並安裝好,安裝的操作非常簡單,用戶可以輕松完成。
操作方法:
1、打開下載好的軟件,直接進入操作主界面,點擊上方左起第一個“添加文件”按鈕,將需要識別的文件按提示添加到軟件中。

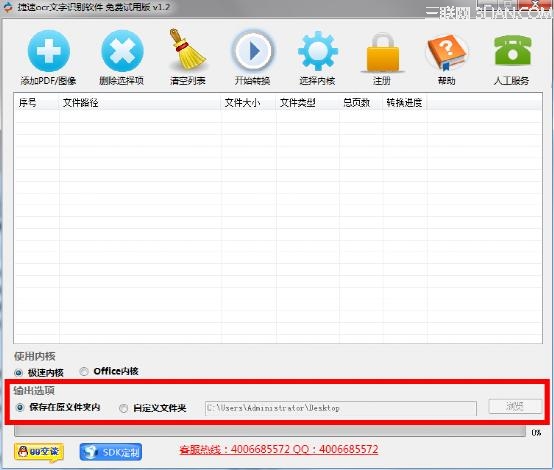
2、看到軟件右下角的“浏覽”按鈕,點擊選擇識別結果存放的路徑,也可以默認不選,這樣就會存放在原文件夾內。
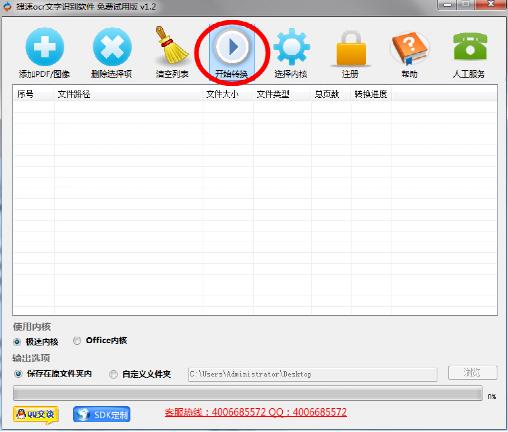
3、上方正中有一個“開始轉換”按鈕,一切准備就緒就可以點擊,然後軟件就會自動對文件進行識別,稍等片刻就能得到識別結果。
- 上一頁:百度雲Web版如何安裝百度影音插件
- 下一頁:單文件版軟件怎麼制作