萬盛學電腦網 >> Linux教程 >> Linux使用S3QL創建加密文件系統的方法
Linux使用S3QL創建加密文件系統的方法
Linux系統操作中,S3QL可用於創建一個加密文件系統,能夠在線存儲數據,那麼基於Amazon S3的S3QL要如何創建一個雲端加密文件系統呢?隨小編一起來了解下吧。
Amazon S3 和 Google Cloud Storage 之類的商業雲存儲服務以能承受的價格提供了高可用性、可擴展、無限容量的對象存儲服務。為了加速這些雲產品的廣泛采用,這些提供商為他們的產品通過明確的 API 和 SDK 培養了一個良好的開發者生態系統。而基於雲的文件系統便是這些活躍的開發者社區中的典型產品,已經有了好幾個開源的實現。
S3QL 便是最流行的開源雲端文件系統之一。它是一個基於 FUSE 的文件系統,提供了好幾個商業或開源的雲存儲後端,比如 Amazon S3、Google Cloud Storage、Rackspace CloudFiles,還有 OpenStack。作為一個功能完整的文件系統,S3QL 擁有不少強大的功能:最大 2T 的文件大小、壓縮、UNIX 屬性、加密、基於寫入時復制的快照、不可變樹、重復數據刪除,以及軟、硬鏈接支持等等。寫入 S3QL 文件系統任何數據都將首先被本地壓縮、加密,之後才會傳輸到雲後端。當你試圖從 S3QL 文件系統中取出內容的時候,如果它們不在本地緩存中,相應的對象會從雲端下載回來,然後再即時地解密、解壓縮。

需要明確的是,S3QL 的確也有它的限制。比如,你不能把同一個 S3FS 文件系統在幾個不同的電腦上同時掛載,只能有一台電腦同時訪問它。另外,ACL(訪問控制列表)也並沒有被支持。
在這篇教程中,我將會描述“如何基於 Amazon S3 用 S3QL 配置一個加密文件系統”。作為一個使用范例,我還會說明如何在掛載的 S3QL 文件系統上運行 rsync 備份工具。
准備工作
本教程首先需要你創建一個 Amazon AWS 帳號(注冊是免費的,但是需要一張有效的信用卡)。
然後 創建一個 AWS access key(access key ID 和 secret access key),S3QL 使用這些信息來訪問你的 AWS 帳號。
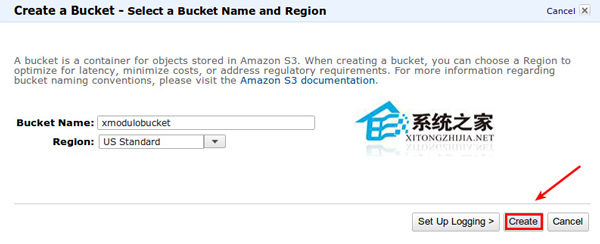
之後通過 AWS 管理面板訪問 AWS S3,並為 S3QL 創建一個新的空 bucket。
為最佳性能考慮,請選擇一個地理上距離你最近的區域。
在 Linux 上安裝 S3QL
在大多數 Linux 發行版中都有預先編譯好的 S3QL 軟件包。
對於 Debian、Ubuntu 或 Linux Mint:
$ sudo apt-get install s3ql
對於 Fedora:
$ sudo yum install s3ql
對於 Arch Linux,使用 AUR。
上一頁12下一頁共2頁
首次配置 S3QL
在 ~/.s3ql 目錄中創建 autoinfo2 文件,它是 S3QL 的一個默認的配置文件。這個文件裡的信息包括必須的 AWS access key,S3 bucket 名,以及加密口令。這個加密口令將被用來加密一個隨機生成的主密鑰,而主密鑰將被用來實際地加密 S3QL 文件系統數據。
$ mkdir ~/.s3ql
$ vi ~/.s3ql/authinfo2
[s3]
storage-url: s3://[bucket-name]
backend-login:[your-access-key-id]
backend-password:[your-secret-access-key]
fs-passphrase:[your-encryption-passphrase]
指定的 AWS S3 bucket 需要預先通過 AWS 管理面板來創建。
為了安全起見,讓 authinfo2 文件僅對你可訪問。
$ chmod 600~/.s3ql/authinfo2
創建 S3QL 文件系統
現在你已經准備好可以在 AWS S3 上創建一個 S3QL 文件系統了。
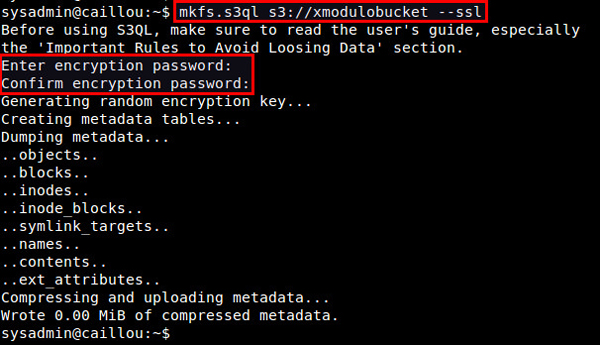
使用 mkfs.s3ql 工具來創建一個新的 S3QL 文件系統。這個命令中的 bucket 名應該與 authinfo2 文件中所指定的相符。使用“--ssl”參數將強制使用 SSL 連接到後端存儲服務器。默認情況下,mkfs.s3ql 命令會在 S3QL 文件系統中啟用壓縮和加密。
$ mkfs.s3ql s3://[bucket-name] --ssl
你會被要求輸入一個加密口令。請輸入你在 ~/.s3ql/autoinfo2 中通過“fs-passphrase”指定的那個口令。
如果一個新文件系統被成功創建,你將會看到這樣的輸出:
掛載 S3QL 文件系統
當你創建了一個 S3QL 文件系統之後,下一步便是要掛載它。
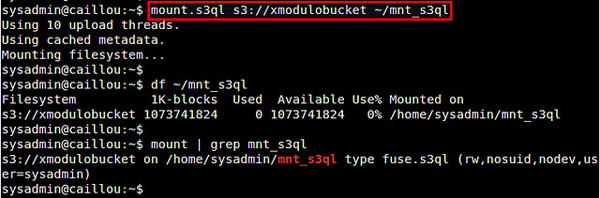
首先創建一個本地的掛載點,然後使用 mount.s3ql 命令來掛載 S3QL 文件系統。
$ mkdir ~/mnt_s3ql
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
掛載一個 S3QL 文件系統不需要特權用戶,只要確定你對該掛載點有寫權限即可。
視情況,你可以使用“--compress”參數來指定一個壓縮算法(如 lzma、bzip2、zlib)。在不指定的情況下,lzma 將被默認使用。注意如果你指定了一個自定義的壓縮算法,它將只會應用到新創建的數據對象上,並不會影響已經存在的數據對象。
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
因為性能原因,S3QL 文件系統維護了一份本地文件緩存,裡面包括了最近訪問的(部分或全部的)文件。你可以通過“--cachesize”和“--max-cache-entries”選項來自定義文件緩存的大小。
如果想要除你以外的用戶訪問一個已掛載的 S3QL 文件系統,請使用“--allow-other”選項。
如果你想通過 NFS 導出已掛載的 S3QL 文件系統到其他機器,請使用“--nfs”選項。
運行 mount.s3ql 之後,檢查 S3QL 文件系統是否被成功掛載了:
$ df ~/mnt_s3ql
$ mount | grep s3ql
卸載 S3QL 文件系統
想要安全地卸載一個(可能含有未提交數據的)S3QL 文件系統,請使用 umount.s3ql 命令。它將會等待所有數據(包括本地文件系統緩存中的部分)成功傳輸到後端服務器。取決於等待寫的數據的多少,這個過程可能需要一些時間。
$ umount.s3ql ~/mnt_s3ql
查看 S3QL 文件系統統計信息及修復 S3QL 文件系統
若要查看 S3QL 文件系統統計信息,你可以使用 s3qlstat 命令,它將會顯示諸如總的數據、元數據大小、重復文件刪除率和壓縮率等信息。
$ s3qlstat ~/mnt_s3ql
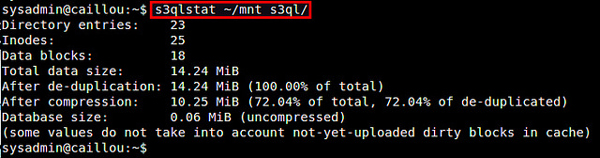
你可以使用 fsck.s3ql 命令來檢查和修復 S3QL 文件系統。與 fsck 命令類似,待檢查的文件系統必須首先被卸載。
$ fsck.s3ql s3://[bucket-name]
S3QL 使用案例:Rsync 備份
讓我用一個流行的使用案例來結束這篇教程:本地文件系統備份。為此,我推薦使用 rsync 增量備份工具,特別是因為 S3QL 提供了一個 rsync 的封裝腳本(/usr/lib/s3ql/pcp.py)。這個腳本允許你使用多個 rsync 進程遞歸地復制目錄樹到 S3QL 目標。
$ /usr/lib/s3ql/pcp.py -h
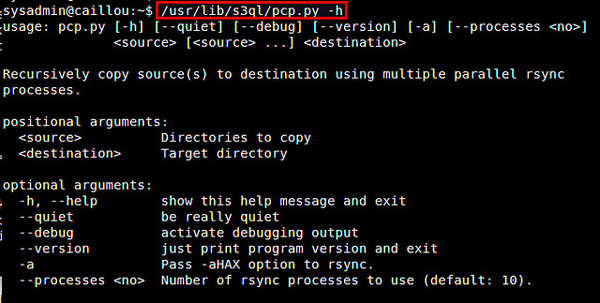
這個命令將會使用 4 個並發的 rsync 連接來備份 ~/Documents 裡的所有內容到一個 S3QL 文件系統。
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4~/Documents ~/mnt_s3ql
這些文件將首先被復制到本地文件緩存中,然後在後台再逐步地同步到後端服務器。
上面就是Linux使用S3QL創建加密文件系統的方法介紹了,此外,S3QL文件系統只能有一台電腦訪問它,不可同時掛載在多個電腦上。
上一頁12 下一頁共2頁


