萬盛學電腦網 >> 數據庫 >> mysql教程 >> mysql數據庫分組(GROUP BY)學習筆記
mysql數據庫分組(GROUP BY)學習筆記
每當查詢數據庫時,想知道有多少類,或想知道找不相同的有多少種,就用到了分組語句group by
使用方法:
代碼如下 復制代碼SELECT * FROM `表名` group by `分組字段`
或帶limit做法
代碼如下 復制代碼SELECT *
FROM `數據表`
GROUP BY `分組的字段`
LIMIT 0 , 30
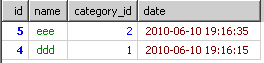
例:(查詢dedecms(織夢)程序的欄目標題表,以欄目id分組)
代碼如下 復制代碼SELECT *
FROM `dede_archives`
GROUP BY `typeid`
LIMIT 0 , 30
關於mysql group by排序問題 .
類如 有一個 帖子的回復表,posts( id , tid , subject , message , dateline ) ,
id為 自動增長字段, tid為該回復的主題帖子的id(外鍵關聯), subject 為回復標題, message 為回復內容, dateline 為回復時間,用UNIX 時間戳表示,
最簡單的 :
SELECT * FROM (SELECT * FROM posts ORDER BY dateline DESC) GROUP BY tid ORDER BY dateline DESC LIMIT 10
也有網友利用自連接實現的 ,這樣的效率應該比上面的子查詢效率高,不過,為了簡單明了,就只用這樣一種了,GROUP BY沒有排序功能,可能是mysql弱智的地方,也許是我還沒有發現,
where+group by(對小組進行排序)
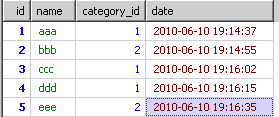
對group by裡的小組進行排序的函數我只查到group_concat()可以進行排序,但group_concat的作用是將小組裡的字段裡的值進行串聯起來。
select group_concat(id order by `date` desc) from `test` group by category_id

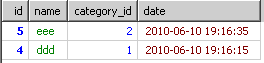
子查詢解決方案