萬盛學電腦網 >> 數據庫 >> mysql教程 >> 分析MYSQL在LINUX上優化三大要點
分析MYSQL在LINUX上優化三大要點
現在MySQL運行的大部分環境都是在Linux上的,如何在Linux操作系統上根據MySQL進行優化,我們這裡給出一些通用簡單的策略。這些方法都有助於改進MySQL的性能。
閒話少說,進入正題。

一、CPU
首先從CPU說起。
你仔細檢查的話,有些服務器上會有的一個有趣的現象:你cat /proc/cpuinfo時,會發現CPU的頻率竟然跟它標稱的頻率不一樣:
#cat /proc/cpuinfo
processor : 5
model name : Intel(R) Xeon(R) CPU E5-2620 0 @2.00GHz
...
cpu MHz : 1200.000
這個是Intel E5-2620的CPU,他是2.00G * 24的CPU,但是,我們發現第5顆CPU的頻率為1.2G。
這是什麼原因呢?
這些其實都源於CPU最新的技術:節能模式。操作系統和CPU硬件配合,系統不繁忙的時候,為了節約電能和降低溫度,它會將CPU降頻。這對環保人士和抵制地球變暖來說是一個福音,但是對MySQL來說,可能是一個災難。
為了保證MySQL能夠充分利用CPU的資源,建議設置CPU為最大性能模式。這個設置可以在BIOS和操作系統中設置,當然,在BIOS中設置該選項更好,更徹底。由於各種BIOS類型的區別,設置為CPU為最大性能模式千差萬別,我們這裡就不具體展示怎麼設置了。
二、內存
然後我們看看內存方面,我們有哪些可以優化的。
i) 我們先看看numa
非一致存儲訪問結構 (NUMA : Non-Uniform Memory Access) 也是最新的內存管理技術。它和對稱多處理器結構 (SMP : Symmetric Multi-Processor) 是對應的。簡單的隊別如下:
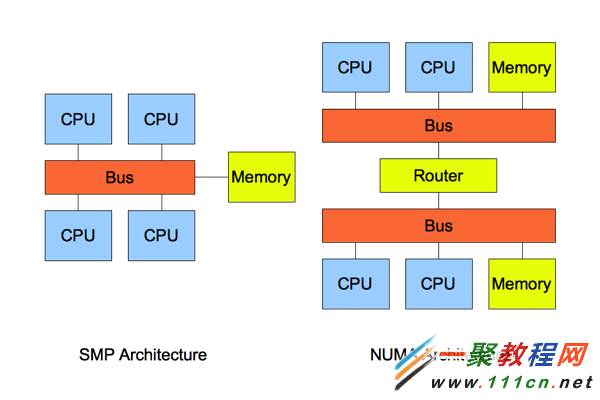
如圖所示,詳細的NUMA信息我們這裡不介紹了。但是我們可以直觀的看到:SMP訪問內存的都是代價都是一樣的;但是在NUMA架構下,本地內存的訪問和非 本地內存的訪問代價是不一樣的。對應的根據這個特性,操作系統上,我們可以設置進程的內存分配方式。目前支持的方式包括:
--interleave=nodes
--membind=nodes
--cpunodebind=nodes
--physcpubind=cpus
--localalloc
--preferred=node
簡而言之,就是說,你可以指定內存在本地分配,在某幾個CPU節點分配或者輪詢分配。除非 是設置為--interleave=nodes輪詢分配方式,即內存可以在任意NUMA節點上分配這種方式以外。其他的方式就算其他NUMA節點上還有內 存剩余,Linux也不會把剩余的內存分配給這個進程,而是采用SWAP的方式來獲得內存。有經驗的系統管理員或者DBA都知道SWAP導致的數據庫性能 下降有多麼坑爹。
所以最簡單的方法,還是關閉掉這個特性。
關閉特性的方法,分別有:可以從BIOS,操作系統,啟動進程時臨時關閉這個特性。
a) 由於各種BIOS類型的區別,如何關閉NUMA千差萬別,我們這裡就不具體展示怎麼設置了。
b) 在操作系統中關閉,可以直接在/etc/grub.conf的kernel行最後添加numa=off,如下所示:
kernel /vmlinuz-2.6.32-220.el6.x86_64 ro root=/dev/mapper/VolGroup-root rd_NO_LUKS LANG=en_US.UTF-8 rd_LVM_LV=VolGroup/root rd_NO_MD quiet SYSFONT=latarcyrheb-sun16 rhgb crashkernel=auto rd_LVM_LV=VolGroup/swap rhgb crashkernel=auto quiet KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM numa=off
另外可以設置 vm.zone_reclaim_mode=0盡量回收內存。
c) 啟動MySQL的時候,關閉NUMA特性:
numactl --interleave=all mysqld &
當然,最好的方式是在BIOS中關閉。
ii) 我們再看看vm.swappiness。
vm.swappiness是操作系統控制物理內存交換出去的策略。它允許的值是一個百分比的值,最小為0,最大運行100,該值默認為60。vm.swappiness設置為0表示盡量少swap,100表示盡量將inactive的內存頁交換出去。
具體的說:當內存基本用滿的時候,系統會根據這個參數來判斷是把內存中很少用到的inactive 內存交換出去,還是釋放數據的cache。cache中緩存著從磁盤讀出來的數據,根據程序的局部性原理,這些數據有可能在接下來又要被讀 取;inactive 內存顧名思義,就是那些被應用程序映射著,但是“長時間”不用的內存。
我們可以利用vmstat看到inactive的內存的數量:
#vmstat -an 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
1 0 0 27522384 326928 1704644 0 0 0 153 11 10 0 0 100 0 0
0 0 0 27523300 326936 1704164 0 0 0 74 784 590 0 0 100 0 0
0 0 0 27523656 326936 1704692 0 0 8 8 439 1686 0 0 100 0 0
0 0 0 27524300 326916 1703412 0 0 4 52 198 262 0 0 100 0 0
通過/proc/meminfo 你可以看到更詳細的信息:
#cat /proc/meminfo | grep -i inact
Inactive: 326972 kB
Inactive(anon): 248 kB
Inactive(file): 326724 kB
這裡我們對不活躍inactive內存進一步深入討論。 Linux中,內存可能處於三種狀態:free,active和inactive。眾所周知,Linux Kernel在內部維護了很多LRU列表用來管理內存,比如LRU_INACTIVE_ANON, LRU_ACTIVE_ANON, LRU_INACTIVE_FILE , LRU_ACTIVE_FILE, LRU_UNEVICTABLE。其中LRU_INACTIVE_ANON, LRU_ACTIVE_ANON用來管理匿名頁,LRU_INACTIVE_FILE , LRU_ACTIVE_FILE用來管理page caches頁緩存。系統內核會根據內存頁的訪問情況,不定時的將活躍active內存被移到inactive列表中,這些inactive的內存可以被 交換到swap中去。
一般來說,MySQL,特別是InnoDB管理內存緩存,它占用的內存比較多,不經常訪問的內存也會不少,這些內存如果被Linux錯誤的交換出去了,將 浪費很多CPU和IO資源。 InnoDB自己管理緩存,cache的文件數據來說占用了內存,對InnoDB幾乎沒有任何好處。
所以,我們在MySQL的服務器上最好設置vm.swappiness=0。
我們可以通過在sysctl.conf中添加一行:
echo "vm.swappiness = 0" >>/etc/sysctl.conf
並使用sysctl -p來使得該參數生效。
三、文件系統
最後,我們看一下文件系統的優化
i) 我們建議在文件系統的mount參數上加上noatime,nobarrier兩個選項。
用noatime mount的話,文件系統在程序訪問對應的文件或者文件夾時,不會更新對應的access time。一般來說,Linux會給文件記錄了三個時間,change time, modify time和access time。
我們可以通過stat來查看文件的三個時間:
stat libnids-1.16.tar.gz
File: `libnids-1.16.tar.gz'
Size: 72309 Blocks: 152 IO Block: 4096 regular file
Device: 302h/770d Inode: 4113144 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access : 2008-05-27 15:13:03.000000000 +0800
Modify: 2004-03-10 12:25:09.000000000 +0800
Change: 2008-05-27 14:18:18.000000000 +0800
其中access time指文件最後一次被讀取的時間,modify time指的是文件的文本內容最後發生變化的時間,change time指的是文件的inode最後發生變化(比如位置、用戶屬性、組屬性等)的時間。一般來說,文件都是讀多寫少,而且我們也很少關心某一個文件最近什 麼時間被訪問了。
所以,我們建議采用noatime選項,這樣文件系統不記錄access time,避免浪費資源。
現在的很多文件系統會在數據提交時強制底層設備刷新cache,避免數據丟失,稱之為write barriers。但是,其實我們數據庫服務器底層存儲設備要麼采用RAID卡,RAID卡本身的電池可以掉電保護;要麼采用Flash卡,它也有自我保 護機制,保證數據不會丟失。所以我們可以安全的使用nobarrier掛載文件系統。設置方法如下:
對於ext3, ext4和 reiserfs文件系統可以在mount時指定barrier=0;對於xfs可以指定nobarrier選項。
ii) 文件系統上還有一個提高IO的優化萬能鑰匙,那就是deadline。
在 Flash技術之前,我們都是使用機械磁盤存儲數據的,機械磁盤的尋道時間是影響它速度的最重要因素,直接導致它的每秒可做的IO(IOPS)非常有限, 為了盡量排序和合並多個請求,以達到一次尋道能夠滿足多次IO請求的目的,Linux文件系統設計了多種IO調度策略,已適用各種場景和存儲設備。
Linux的IO調度策略包括:Deadline scheduler,Anticipatory scheduler,Completely Fair Queuing(CFQ),NOOP。每種調度策略的詳細調度方式我們這裡不詳細描述,這裡我們主要介紹CFQ和Deadline,CFQ是Linux內 核2.6.18之後的默認調度策略,它聲稱對每一個 IO 請求都是公平的,這種調度策略對大部分應用都是適用的。但是如果數據庫有兩個請求,一個請求3次IO,一個請求10000次IO,由於絕對公平,3次IO 的這個請求都需要跟其他10000個IO請求競爭,可能要等待上千個IO完成才能返回,導致它的響應時間非常慢。並且如果在處理的過程中,又有很多IO請 求陸續發送過來,部分IO請求甚至可能一直無法得到調度被“餓死”。而deadline兼顧到一個請求不會在隊列中等待太久導致餓死,對數據庫這種應用來 說更加適用。
實時設置,我們可以通過
echo deadline >/sys/block/sda/queue/scheduler
來將sda的調度策略設置為deadline。
我們也可以直接在/etc/grub.conf的kernel行最後添加elevator=deadline來永久生效。
總結
CPU方面:
關閉電源保護模式
內存:
vm.swappiness = 0
關閉numa
文件系統:
用noatime,nobarrier掛載系統
IO調度策略修改為deadline。



