萬盛學電腦網 >> 網絡編程 >> php編程 >> DOM基礎及php讀取xml內容操作的方法
DOM基礎及php讀取xml內容操作的方法
DOM(Document Object Model):文檔對象模型。核心思想是:把 xml文件看作是一個對象模型,然後通過對象的方式來操作 xml 文件。
php對xml文檔進行增刪改查(curd)操作,具體分析如下:
xml文檔:class.xml
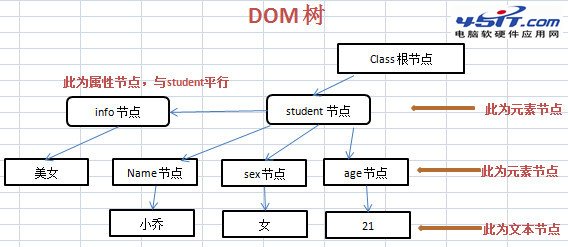
代碼如下: <?xml version="1.0" encoding="utf-8"?><class>
<student info="美女">
<name>小喬</name>
<sex>女</sex>
<age>20</age>
</student>
<student>
<name>周瑜</name>
<sex>男</sex>
<age>25</age>
</student>
</class>
class.xml 對應的 DOM 樹結構圖
php文件(對xml文檔操作)
查詢操作案例:
代碼如下: <?php//1、創建一個DOMDocument對象。該對象就表示 xml文件
$xmldoc = new DOMDocument();
//2、加載xml文件(指定要解析哪個xml文件,此時dom樹節點就會加載到內存中)
$xmldoc->load("class.xml");
//3、目標:獲取第一個學生的名字
//3.1 第一步,讀取所有的學生
$students = $xmldoc->getElementsByTagName("student");//方法getElementsByTagName:根據所給的節點名字(這裡是student)查找 相應的節點,返回 DOMNodeList類型的對象,相當於取出了所有的學生。可以用var_dump($students)查看,並根據返回值查找手冊,看其下面的屬性與方法。
echo "共有 ".$students->length."個學生<br />";
//3.2 讀取第一個學生
$stu1 = $students->item(0);//讀取到第一個學生。返回值為DOMElement對象。直接 echo $stu1->nodeValue;則把name,sex,age都輸出。
//3.3 取出第一個學生的名字
$stu1_name = $stu1->getElementsByTagName("name");
//3.4 讀取到名字
echo $stu1_name->item(0)->nodeValue;
?>
注意點:
(1)編碼問題;
(2)這裡只是基礎演示,比較麻煩,後面用到循環和函數來操作;
(3)用var_dump(),查看變量的返回值是什麼,再根據返回值到手冊中查找該返回值下的屬性與方法。
(4)整個順序下來,getElementByTagName()並不需要一層一層的讀,事實上可以直接讀取到節點name的,而不需要先讀取student(當然,如果同一個student下,有多個name,就會出問題了,這裡就需要學習新的知識點xpath)。
所以上面這代碼可以簡單改為:
代碼如下: <?php//1、創建一個DOMDocument對象。該對象就表示 xml文件
$xmldoc = new DOMDocument();
//2、加載xml文件(指定要解析哪個xml文件,此時dom樹節點就會加載到內存中)
$xmldoc->load("class.xml");
//3、目標:獲取第一個學生的名字
$stu = $xmldoc->getElementsByTagName("name");//直接找到節點name
$stu1 = $stu->item(0);// item(1)時,可以取到周瑜
echo $stu1->nodeValue;
?>
php編程排行
程序編程推薦
相關文章




copyright © 萬盛學電腦網 all rights reserved