SQL語句優化我們除利用自己的經驗來進行優化之外還有其它的一些工具與命令了,下面我們來看加速MySQL SQL語句優化的一些命令方法吧.
引言
優化SQL,是DBA常見的工作之一。如何高效、快速地優化一條語句,是每個DBA經常要面對的一個問題。在日常的優化工作中,我發現有很多操作是在優化過程中必不可少的步驟。然而這些步驟重復性的執行,又會耗費DBA很多精力。於是萌發了自己編寫小工具,提高優化效率的想法。
那選擇何種語言來開發工具呢?
對於一名DBA來說,掌握一門語言配合自己的工作是非常必要的。相對於shell的簡單、perl的飄逸,Python是一種嚴謹的高級語言。其具備上手快、語法簡單、擴展豐富、跨平台等多種優點。很多人把它稱為一種“膠水”語言,通過大量豐富的類庫、模塊,可以快速搭建出自己需要的工具。
於是乎,這個小工具就成了我學習Python的第一個作業,我把它稱之為“MySQL語句優化輔助工具”。而且從此以後,我深深愛上了Python,並開發了很多數據庫相關的小工具,以後有機會介紹給大家。
一、優化手段、步驟
下面在介紹工具使用之前,首先說明下MySQL中語句優化常用的手段、方法及需要注意的問題。這也是大家在日常手工優化中,需要了解掌握的。
1、執行計劃 — EXPLAIN命令
執行計劃是語句優化的主要切入點,通過執行計劃的判讀了解語句的執行過程。在執行計劃生成方面,MySQL與Oracle明顯不同,它不會緩存執行計劃,每次都執行“硬解析”。查看執行計劃的方法,就是使用EXPLAIN命令。
基本用法
當在一個Select語句前使用關鍵字EXPLAIN時,MySQL會解釋了即將如何運行該Select語句,它顯示了表如何連接、連接的順序等信息。
當使用EXTENDED關鍵字時,EXPLAIN產生附加信息,可以用SHOW WARNINGS浏覽。該信息顯示優化器限定SELECT語句中的表和列名,重寫並且執行優化規則後SELECT語句是什麼樣子,並且還可能包括優化過程的其它注解。在MySQL5.0及更新的版本裡都可以使用,在MySQL5.1裡它有額外增加了一個過濾列(filtered)。
顯示的是查詢要訪問的數據分片——如果有分片的話。它只能在MySQL5.1及更新的版本裡使用。
-
EXPLAIN FORMAT=JSON (5.6新特性)
另一個格式顯示執行計劃。可以看到諸如表間關聯方式等信息。
輸出字段
下面說明一下EXPLAIN輸出的字段含義,並由此學習如何判斷一個執行計劃。
MySQL選定的執行計劃中查詢的序列號。如果語句裡沒有子查詢等情況,那麼整個輸出裡就只有一個SELECT,這樣一來每一行在這個列上都會顯示一個1。如果語句中使用了子查詢、集合操作、臨時表等情況,會給ID列帶來很大的復雜性。如上例中,WHERE部分使用了子查詢,其id=2的行表示一個關聯子查詢。
語句所使用的查詢類型。是簡單SELECT還是復雜SELECT(如果是後者,顯示它屬於哪一種復雜類型)。常用有以下幾種標記類型。
-
DEPENDENT SUBQUERY
子查詢內層的第一個SELECT,依賴於外部查詢的結果集。
-
DEPENDENT UNION
子查詢中的UNION,且為UNION中從第二個SELECT開始的後面所有SELECT,同樣依賴於外部查詢的結果集。
-
PRIMARY
子查詢中的最外層查詢,注意並不是主鍵查詢。
-
SIMPLE
除子查詢或UNION之外的其他查詢。
-
SUBQUERY
子查詢內層查詢的第一個SELECT,結果不依賴於外部查詢結果集。
-
UNCACHEABLE SUBQUERY
結果集無法緩存的子查詢。
-
UNION
UNION語句中的第二個SELECT開始後面的所有SELECT,第一個SELECT為PRIMARY。
-
UNION RESULT
UNION中的合並結果。從UNION臨時表獲取結果的SELECT。
-
DERIVED
衍生表查詢(FROM子句中的子查詢)。MySQL會遞歸執行這些子查詢,把結果放在臨時表裡。在內部,服務器就把當做一個”衍生表”那樣來引用,因為臨時表就是源自子查詢。
這一步所訪問的數據庫中表的名稱或者SQL語句指定的一個別名表。這個值可能是表名、表的別名或者一個為查詢產生的臨時表的標識符,如派生表、子查詢或集合。
表的訪問方式。以下列出了各種不同類型的表連接,依次是從最好的到最差的。
-
system
系統表,表只有一行記錄。這是const表連接類型的一個特例。
-
const
讀常量,最多只有一行匹配的記錄。由於只有一行記錄,優化程序裡該行記錄的字段值可以被當作是一個恆定值。const用於在和PRIMARY KEY或UNIQUE索引中有固定值比較的情形。
-
eq_ref
最多只會有一條匹配結果,一般是通過主鍵或唯一鍵索引來訪問。從該表中會有一行記錄被讀取出來以和從前一個表中讀取出來的記錄做聯合。與const類型不同的是,這是最好的連接類型。它用在索引所有部分都用於做連接並且這個索引是一個PRIMARY KEY或UNIQUE類型。eq_ref可以用於在進行”=”做比較時檢索字段。比較的值可以是固定值或者是表達式,表達示中可以使用表裡的字段,它們在讀表之前已經准備好了。
-
ref
JOIN語句中驅動表索引引用的查詢。該表中所有符合檢索值的記錄都會被取出來和從上一個表中取出來的記錄作聯合。ref用於連接程序使用鍵的最左前綴或者是該鍵不是PRIMARY KEY或UNIQUE索引(換句話說,就是連接程序無法根據鍵值只取得一條記錄)的情況。當根據鍵值只查詢到少數幾條匹配的記錄時,這就是一個不錯的連接類型。ref還可以用於檢索字段使用”=”操作符來比較的時候。
-
ref_or_null
與ref的唯一區別就是在使用索引引用的查詢之外再增加一個空值的查詢。這種連接類型類似ref,不同的是MySQL會在檢索的時候額外的搜索包含NULL值的記錄。這種連接類型的優化是從MySQL 4.1.1開始的,它經常用於子查詢。
-
index_merge
查詢中同時使用兩個(或更多)索引,然後對索引結果進行合並(merge),再讀取表數據。這種連接類型意味著使用了Index Merge優化方法。
-
unique_subquery
子查詢中的返回結果字段組合是主鍵或唯一約束。
-
index_subquery
子查詢中的返回結果字段組合是一個索引(或索引組合),但不是一個主鍵或唯一索引。這種連接類型類似unique_subquery。它用子查詢來代替IN,不過它用於在子查詢中沒有唯一索引的情況下。
-
range
索引范圍掃描。只有在給定范圍的記錄才會被取出來,利用索引來取得一條記錄。
-
index
全索引掃描。連接類型跟ALL一樣,不同的是它只掃描索引樹。它通常會比ALL快點,因為索引文件通常比數據文件小。MySQL在查詢的字段知識單獨的索引的一部分的情況下使用這種連接類型。
-
fulltext
全文索引掃描。
-
all
全表掃描。
該字段是指MySQL在搜索表記錄時可能使用哪個索引。如果沒有任何索引可以使用,就會顯示為null。
查詢優化器從possible_keys中所選擇使用的索引。key字段顯示了MySQL實際上要用的索引。當沒有任何索引被用到的時候,這個字段的值就是NULL。
被選中使用索引的索引鍵長度。key_len字段顯示了MySQL使用索引的長度。當key字段的值為NULL時,索引的長度就是NULL。
列出是通過常量,還是某個表的某個字段來過濾的。ref字段顯示了哪些字段或者常量被用來和key配合從表中查詢記錄出來。
該字段顯示了查詢優化器通過系統收集的統計信息估算出來的結果集記錄條數。
該字段顯示了查詢中MySQL的附加信息。
這個列式在MySQL5.1裡新加進去的,當使用EXPLAIN EXTENDED時才會出現。它顯示的是針對表裡符合某個條件(WHERE子句或聯接條件)的記錄數的百分比所作的一個悲觀估算。
SQL改寫
EXPLAIN除了可以顯示執行計劃外,還可以顯示SQL改寫。所謂SQL改寫,是指MySQL在對SQL語句進行優化前,會基於一些原則進行語句的改寫,以方便後面的優化器進行優化生成更優的執行計劃。該功能是通過EXPLAIN EXTENDED+SHOW WARNINGS配合使用。下面通過示例說明一下。
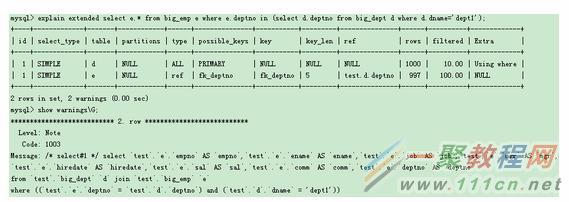
從上面示例中,可看到原有語句中的IN子查詢被改寫成為表間關聯的方式。
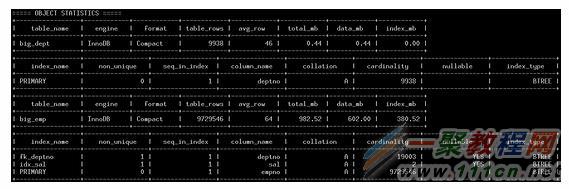
2、統計信息
查看統計信息也是優化語句中必不可少的一步。通過統計信息可以快速了解對象的存儲特征如何。下面說明主要的兩類統計信息——表、索引。
表統計信息 — SHOW TABLE STATUS
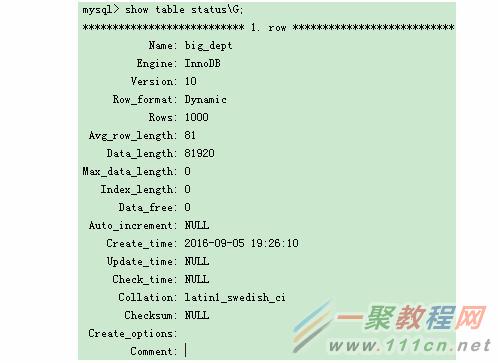
-
Name: 表名
-
Engine: 表的存儲引擎類型(ISAM、MyISAM或InnoDB)
-
Row_format: 行存儲格式(Fixed-固定的、Dynamic-動態的或Compressed-壓縮的)
-
Rows: 行數量。在某些存儲引擎中,例如MyISAM和ISAM他們存儲了精確的記錄數。不過其他存儲引擎中,它可能只是近似值。
-
Avg_row_length: 平均行長度。
-
Data_length: 數據文件的長度。
-
Max_data_length: 數據文件的最大長度。
-
Index_length: 索引文件的長度。
-
Data_free: 已分配但未使用了字節數。
-
Auto_increment: 下一個autoincrement(自動加1)值。
-
Create_time: 表被創造的時間。
-
Update_time: 數據文件最後更新的時間。
-
Check_time: 最後對表運行一個檢查的時間。執行mysqlcheck命令後更新,僅對MyISAM有效。
-
Create_options: 額外留給CREATE TABLE的選項。
-
Comment: 當創造表時,使用的注釋(或為什麼MySQL不能存取表信息的一些信息)。
-
Version: 數據表的’.frm’文件版本號。
-
Collation: 表的字符集和校正字符集。
-
Checksum: 實時的校驗和值(如果有的話)。
3、索引統計信息 — SHOW INDEX

-
Table: 表名。
-
Non_unique: 0,如果索引不能包含重復。
-
Key_name: 索引名
-
Seq_in_index: 索引中的列順序號,從1開始。
-
Column_name: 列名。
-
Collation: 列怎樣在索引中被排序。在MySQL中,這可以有值A(升序)或NULL(不排序)。
-
Cardinality: 索引中唯一值的數量。
-
Sub_part: 如果列只是部分被索引,索引字符的數量。當整個字段都做索引了,那麼它的值是NULL。
-
Packed: 表示鍵值是如何壓縮的,NULL表示沒有壓縮。
-
Null: 當字段包括NULL的記錄是YES,它的值為,反之則是”。
-
Index_type: 使用了哪種索引算法(有BTREE、FULLTEXT、HASH、RTREE)。
-
Comment: 備注。
-
系統參數: 系統參數也會影響語句的執行效率。查看系統參數,可使用SHOW VARIABLES命令。
參數說明
系統參數很多,下面介紹幾個。
排序區大小。其大小直接影響排序使用的算法。如果系統中排序都比較大、內存充足且並發量不是很大的情況,可以適當增加此參數。這個參數是針對單個Thead的。
Join操作使用內存區域大小。只有當Join是ALL、index、range或index_merge時使用到Join Buffer。如果join語句較多,可以適當增大join_buffer_size。需要注意到是,這個值針對單個Thread。每個Thread都會自己創建獨立的Buffer,而不是整個系統共享的Buffer,不要設置過大而造成系統內存不足。
如果內存內的臨時表超過該值,MySQL自動將它轉換為硬盤上的MyISAM表。如果執行許多高級GROUP BY查詢並且有大量內存,則可以增加tmp_table_size的值。
讀查詢操作所能使用的緩沖區大小。這個參數是針對單個Thead的。
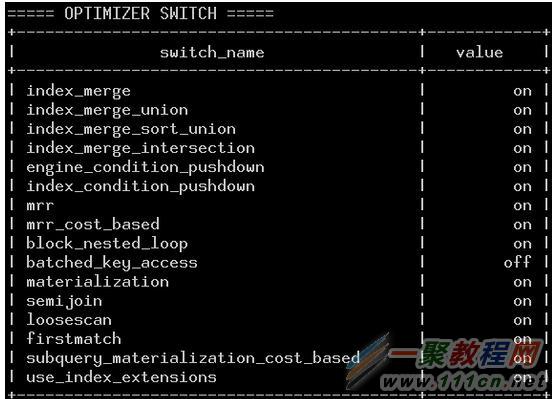
4、優化器開關
在MySQL中,還有一些參數是可以用來控制優化器行為的。
參數說明
這個參數控制優化器在窮舉執行計劃時的限度。如果查詢長時間處於”statistics”狀態,可以考慮調低此參數。
默認是打開的,這讓優化器會根據需要掃描的行數來決定是否跳過某些執行計劃。
這個變量包含了一些開啟/關閉優化器特性的標志位。
示例 — 干預優化器行為(ICP特性)
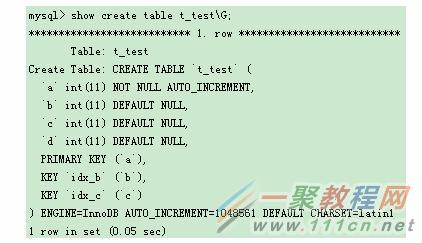
默認情況下,ICP特性是開啟的。查看一下優化器行為。

基於二級索引的過濾查詢,使用了ICP特性,從Extra中的”Using index condition”可見。如果通過優化器開關,干預優化器行為,又會如何呢?
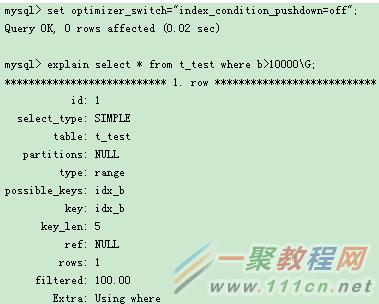
從Extra可見,ICP特性已經禁用。
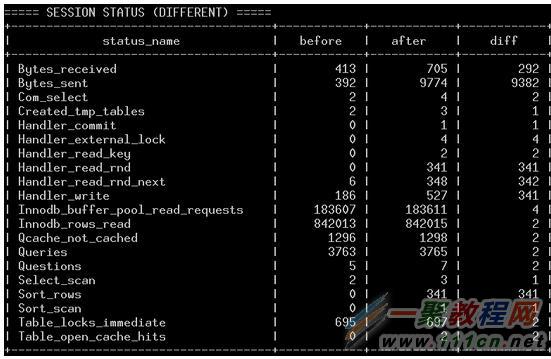
5、系統狀態(SHOW STATUS)
MySQL中也內置了一些狀態,通過這些狀態變量也可反映出語句執行的一些情況,方便定位問題。手工執行的話,可以在執行語句的前後分別執行SHOW STATUS命令,查看狀態的變化。當然,因狀態變量很多,對比起來不太方便,後面我介紹的小工具,可以解決這個問題。
狀態變量
狀態變量很多,這裡介紹幾個。
排序算法已經執行的合並的數量。如果這個變量值較大,應考慮增加sort_buffer_size系統變量的值。
在范圍內執行的排序的數量。
已經排序的行數。
通過掃描表完成的排序的數量。
索引中第一條被讀的次數。讀取索引頭的次數,如果這個值很高,說明全索引掃描很多。
根據鍵讀一行的請求數。如果較高,說明查詢和表的索引正確。
按照鍵順序讀下一行的請求數。如果你用范圍約束或如果執行索引掃描來查詢索引列,該值增加。
按照鍵順序讀前一行的請求數。
根據固定位置讀一行的請求數。如果執行大量查詢並需要對結果進行排序該值較高。則可能使用了大量需要MySQL掃描整個表的查詢或連接沒有正確使用鍵。
在數據文件中讀下一行的請求數。如果正進行大量的表掃描,該值較高。通常說明表索引不正確或寫入的查詢沒有利用索引。
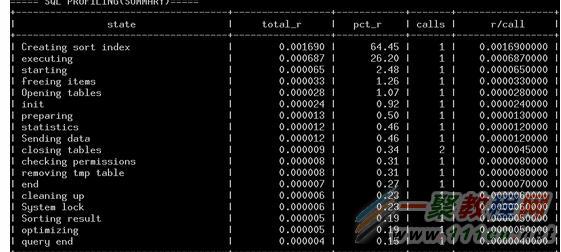
6、SQL性能分析器(Query Profiler)
MySQL的Query Profiler是一個使用非常方便的Query診斷分析工具,通過該工具可以獲取一條Query在整個執行過程中多種資源的消耗情況,如CPU、IO、IPC、SWAP等,以及發生的PAGE FAULTS、CONTEXT SWITCHE等,同時還能得到該Query執行過程中的MySQL所調用的各個函數在源文件中的位置。
使用方法
mysql> select @@profiling;
mysql> set profiling=1;
默認情況下profiling的值為0表示MySQL SQL Profiler處於OFF狀態,開啟SQL性能分析器後profiling的值為1。
mysql> select count(*) from t1;
使用”show profile”命令獲取當前系統中保存的多個Query的profile的概要信息。
mysql> show profiles;
+———-+————+———————–+
| Query_ID | Duration | Query |
+———-+————+———————–+
| 1 | 0.00039300 | select count(*) from t1 |
+———-+————+———————–+
在獲取概要信息之後,就可以根據概要信息的Query_ID來獲取某個Query的執行過程中詳細的profile信息。
mysql> show profile for query 1;
mysql> show profile cpu,block io for query 1;
二、工具說明
前面談到了多種手段,對於SQL語句的調優都有所幫助。通過下面這個小工具,可以自動調用命令將上面這些內容一次性推給DBA,大大加速優化的過程。
1、准備條件
-
模塊 – MySQLDB
-
模塊 – sqlparse
-
Python版本 = 2.7.3 (2.6.x版本應該也沒問題,3.x版本沒測試)
2、調用方法
python mysql_tuning.py -p tuning_sql.ini -s ‘select xxx’
參數說明
-p 指定配置文件名稱
-s 指定SQL語句
3、配置文件
共分兩節信息,分別是[database]描述數據庫連接信息,[option]運行配置信息。
[database]
server_ip = 127.0.0.1
db_user = testuser
db_pwd = testpwd
db_name = test
[option]
sys_parm = ON //是否顯示系統參數
sql_plan = ON //是否顯示執行計劃
obj_stat = ON //是否顯示相關對象(表、索引)統計信息
ses_status = ON //是否顯示運行前後狀態信息(激活後會真實執行SQL)
sql_profile = ON //是否顯示PROFILE跟蹤信息(激活後會真實執行SQL)
4、輸出說明
標題部分
包含運行數據庫的地址信息及數據版本信息。
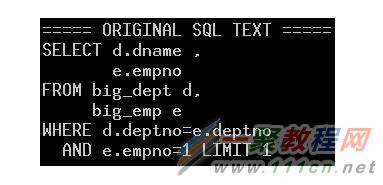
原始SQL
用戶執行輸入的SQL,這部分主要是為了後續對比SQL改寫時使用。語句顯示時使用了格式化。
系統級參數
腳本選擇顯示了部分與SQL性能相關的參數。這部分是寫死在代碼中的,如需擴展需要修改腳本。
優化器開關
下面是和優化器相關的一些參數,通過調整這些參數可以人為干預優化器行為。
執行計劃
就是調用explain extended的輸出結果。如果結果過長,可能出現顯示串行的問題(暫時未解決)。
優化器改寫後的SQL
通過這裡可判斷優化器是否對SQL進行了某種優化(例如子查詢的處理)。

統計信息
在SQL語句中所有涉及到的表及其索引的統計信息都會在這裡顯示出來。
運行狀態信息
在會話級別對比了執行前後的狀態(SHOW STATUS),並將出現變化的部分顯示出來。需要注意的是,因為收集狀態數據是采用SELECT方式,會造成個別指標的誤差(例如Com_select)。
PROFILE詳細信息
調用SHOW PROFILE得到的詳細信息。
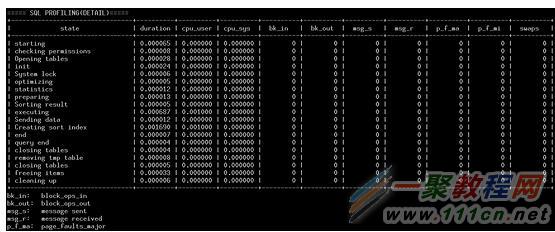
PROFILE匯總信息
根據PROFILE的資源消耗情況,顯示不同階段消耗對比情況(TOP N),直觀顯示”瓶頸”所在。