萬盛學電腦網 >> 網絡基礎知識 >> 遞歸神經網絡不可思議的有效性
遞歸神經網絡不可思議的有效性
遞歸神經網絡(RNNs)有一些不可思議的地方。我仍然記得我訓練的第一個用於 圖片字幕的遞歸網絡。從花幾十分鐘訓練我的第一個嬰兒模型(相當隨意挑選的超參數)開始,到訓練出能夠針對圖像給出有意義描述的模型。有些時候,模型對於輸出結果質量的簡單程度的比例,會與你的期望相差甚遠,而這還僅僅是其中一點。有如此令人震驚結果,許多人認為是因為RNNs非常難訓練(事實上,通過多次試驗,我得出了相反的結論)。一年前:我一直在訓練RNNs,我多次見證了它們的強大的功能和魯棒性,而且它們的輸出結果同樣讓我感到有趣。這篇文章將會給你展現它不可思議的地方。 dedecms.com
我們將訓練一個RNNs讓它一個字符一個字符地生成文本,然後我們思考“這怎麼可能?” 織夢內容管理系統
順便說句,在講述這篇文章的同時,我同樣會將代碼上傳到 Github 上,這樣你就可以基於多層LSTMs來訓練字符級語言模型。你向它輸入大量的文本,它會學習並產生類似的文本。你也可以用它來重新運行我下面的代碼。但是我們正在不斷超越自己;那麼RNNs究竟是什麼呢? copyright dedecms
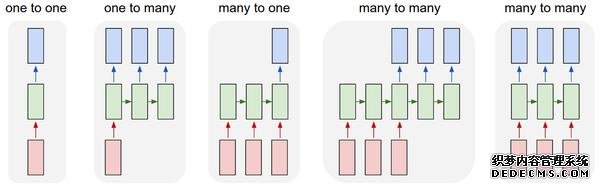
遞歸神經網絡序列。你可能會問:是什麼讓遞歸神經網絡如此特殊?Vanilla神經網絡(卷積網絡也一樣)最大的局限之處就是它們API的局限性:它們將固定大小的向量作為輸入(比如一張圖片),然後輸出一個固定大小的向量(比如不同分類的概率)。還不止這些:這些模型按照固定的計算步驟來(比如模型中層的數量)實現這樣的輸入輸出。遞歸網絡更令人興奮的主要原因是,它允許我們對向量序列進行操作:輸入序列、輸出序列、或大部分的輸入輸出序列。通過幾個例子可以具體理解這點: 織夢好,好織夢
 織夢內容管理系統
織夢內容管理系統
dedecms.com
網絡基礎知識排行




copyright © 萬盛學電腦網 all rights reserved