萬盛學電腦網 >> 網頁制作 >> 交互設計 >> 用戶開口說話怎麼就那麼難
用戶開口說話怎麼就那麼難
老羅曾經說:“語音識別技術的使用上,無論是siri還是它的模仿者,都從根上就犯了錯,所以都是熱鬧一陣就過去了,幾乎沒人認真用它(因為不好用+用起來顯得巨傻)。”雖然說的有些偏激,但是沒人認真用也就是說大家不願意開口說話這件事情是值得思考的,語音識別技術這個根正苗紅的太子發展到現在,試圖滲透著我們生活的同時,我們也發現這玩意兒看起來並沒有傳說的那麼神乎其神,從語音機器人到Siri再到Google Glass,每一次相關產品的問世都引起極大的關注度,但又隨著時間和了解逐漸平息下來,到底是什麼讓我們覺得巨傻而難開金口呢?
市場現狀
首先來看下目前常見的語音類產品:
一、手機領域:微信、語音助手、聽歌搜索
二、PC領域:語音聊天、外語教學軟件、盲人輔助軟件
三、其他設配領域:Google Glass、車載系統

圖1:寶馬公司旗下車載語音控制系統,駕駛員只要按方向盤的控制鍵,激活語音輔助系統,通過聲音就能夠發送信息、打電話以及使用其他語音指令。
圖2: Google Glass。
圖3:盲人閱讀器。
圖4:Duolingo外語學習軟件,通過語音練習聽說。
使用習慣分析
他們有的涉及識別,有的不涉及,但從以上這些產品中,可以發現幾個有趣的現象:
1.在手機這個領域,聽歌搜索這個細分領域的識別還是很准確的;
2.由於微信的教育,可以見到越來越多的人在公共場合對著手機說話,語音的溝通方式已經沒有顯得那麼不自然了,用戶習慣逐漸形成;
3.外語教學和盲人輔助類的軟件都有他們的特有的市場,競爭壁壘高也容易取得了成績;
4.其他設備領域雖然尚屬新興,但由於其設備條件和配備場景的特殊性和前瞻性,是發展滲透的趨勢。
問題和解決方案
通過以上這些發現,不難看出人們在使用語音進行人機交互時遇到的問題,方便我們借助設計手段提升用戶開口說話的欲望:
識別的准確率
環境噪音、硬件設備的條件、技術的限制都會降低識別的准確率,和人們表達能力的差異性以及人們理解能力的廣泛性相比起來,技術和人還不能相比,因此在試過幾次之後,我們說話時會變得咬文嚼字小心翼翼。
那麼從交互的角度,我們將“小心翼翼”的問題拆開來細看,有一些辦法可以優化甚至解決:
1.不知道對准哪裡說——應用中最大的call to action語音按鈕置於麥克風附近,例如iPhone的麥克風在手機的下部,Siri的按鈕和聲波動效反饋也都在手機下部,用戶自然形成對准手機下部說話的條件反射;
2.不知道何時開始/結束說話——長按進行語音錄入。第一,長按作為語音錄入方式已經形成用戶習慣,不僅可以應用在社交軟件領域,也可以應用到語音識別的場景;第二,長按對於語音錄入的開始或者結尾是由人自己進行控制,相比機器判斷更加准確,利於屏蔽不必要的噪音;(例如:百度語音助手Android版)
3.識別語言不清晰——進行有效的提示和引導。一種情況下識別的結果不唯一,可以通過置信區間的判斷給出用戶更多的結果建議,或者提供可供修改的部分和候選項來降低用戶心理挫敗感和降低修改成本。(例如:百度地圖語音輸入查找地點“鵬寰大廈”後提供的搜索建議列表)。
情感因素
人機對話過程可以拆分為三個階段:人的語音輸入→語言識別、分析→機器的回答反饋。
從體驗設計的角度來思考解決方案,第一階段尤其是在公共場合下,對著一個機器用咬文嚼字的腔調說話略顯奇特,從交互的角度來看,我們可以:
1. 提供備選輸入方式——鍵盤輸入;
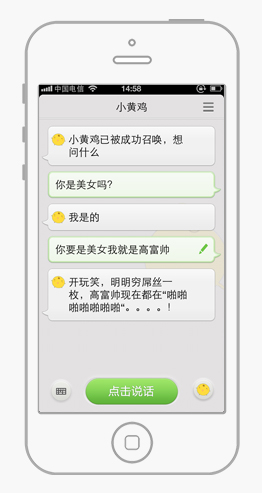
2. 分層收斂——進入足夠垂直的場景,減少不必要的干擾因素(例如:百度語音助手“召喚小黃雞”進入小黃雞對話場景,在這裡就是打趣,和打趣無關的一切事情皆被拋開,發揮想象力,我們可以把“打趣”換成任意一個場景);
3. 模擬已有的使用習慣。例如把電話拿到耳邊這個行為,它具有足夠的針對性指向打電話的場景,如錘子系統語音打電話功能,直接把電話拿到耳邊說出姓名即可開始撥打電話,省去操作步驟,也免去讓別人覺得自己奇怪的心理顧慮。
在人機對話過程的第三階段機器的回答中,因機器固定的語調、缺乏情感色彩的答案等略顯冰冷,可以采取擬人化的場景設計或者豐富的語音播報類型舒緩緊繃的神經。(例如:天氣通提供各種方言或者明星播報天氣狀況,增加趣味性)
其它
而以上這些都影響著用戶再次使用的行為,還有其他的一些點值得入手:
1.在產品定位的選取上,不論你是從教育的角度入手,還是幫助殘障人士,亦或是完全趣味性的探索,都能找到爭當居家旅行殺人滅口必備產品的手段;
2.在某些特殊場合下,肢體或視線被占用時,用語音交流也是較好的方案,如開車時提供語音對車內功能進行操作、做飯時參考菜譜等;
3.細分場景進行特殊優化,如建提醒、聽播報。

- 上一頁:交互設計在產品中所傳遞的身份認同
- 下一頁:互聯網設計趨勢



